
(TrafficJAM) 교통제어 강화학습 논문 정리 - IntelliLight, A Reinforcement Learning Approach for Intelligent Traffic Light Control by Hua Wei(2018)
by 줌코딩
요약 목적
- 이 자료는 개인 프로젝트를 진행하기 위함이라 강화학습 쪽으로 많이 편중될 수 있음을 참고하길 바란다.
- 현재 github에 이 논문을 코드로 옮겨놓은 것이 있어서, 논문을 이해하고 그 코드를 따라가보려 한다.
Abstract
- 기존 연구는 실제 교통 데이터에 테스트해보지 못했고, policy에 대한 해석이 없이 reward에 대한 연구에만 편중되어 있으나, 본 연구는 실제 데이터를 기반으로 policy를 심도있게 해석해볼 것이다.
Introduction
- 기존 RL 연구는 두가지 이유로 어려움을 겪었다.
- 첫번째는 환경을 나타내는 방법이고 둘째는 환경과 결정과의 관계를 모델하는 방법이다.
- 이 문제를 해결하는 방법으로 제안된 것이 Deep Q-learning(DQN)이다.
- DQN에서 Environment은 traffic light phase와 traffic conidtion으로 나타내고.
- State는 Environment의 여러 feature를 표현한 것이다.
- Agent는 state를 input으로 받아 모델을 이용해서 현재 신호를 유지하는 게 좋을지 바꾸는 게 좋을지 예측한다.
- 이 결정은 environtment에 전달되고 이에 따라 reward가 주어진다.
- reward를 받은 agent는 model을 업데이트하고 다음 stamp에서 새로운 state와 model을 이용해서 또다른 결정을 내린다.
- 본 연구는 3가지 관점에서 다른 연구와 차별점을 가진다.
- 첫째로, 실제 교통 데이터로 실험을 진행하였다.(중국의 도시들의 교통 영상 데이터 활용)
- 둘째로, policy 자체를 분석했다.(reward가 같아도 좋은 policy와 그렇지 않은 policy가 존재할 수 있기 때문이다.)
- 마지막으로, 과거 연구들은 phase에 여러가지 feature를 추가해서 진행하였는데 다른 feature들 때문에 phase가 모델을 만드는데 영향력을 발휘하지 못하는 경우가 있었다.
- 이를 위해 phase-sensitive한 RL agent를 제안한다.
Reinforcement Learning for Traffic Light Control
- 기존의 discrete state-action pair value가 엄청나게 많은 공간을 차지했었기 때문에 이를 개선할 방법이 필요했다.
- 이를 위해 Q-function을 사용해서 state, action, reward를 모두 연결시켰다.
- 과거 연구는 reward에만 집중했고 실제 교통환경의 유동성은 간과했다.
- 때문에 학습된 신호 변화에 대해 설명이 어려웠다.
- 본 연구에서는 보다 실제적인 환경에서 알고리즘을 테스트하고 reward보다 policy 측면에서의 분석을 진행하였다.
Problem Definition
- 주어진 state에 대해서 최적의 action을 취해서 reward를 최대화하라.
Framework
- 모델은 두 부분으로 구성되어있는데 offline part와 online part이다.
- offline에서는 각 신호등의 시간을 정해놓고 data sample만 받아낸다.
- 그렇게 sample이 모아지면, 모델이 본격적으로 online stage로 넘어간다.
- online에서는 agent가 각시간대별 state를 관찰하고 action을 취한다.
- action을 선택함에 있어서는 $\epsilon$-greedy strategy를 이용하여 exploration과 exploitation을 하게 된다.
- 그후 action에 따른 reward를 확인하고 (s, a, r)의 형태로 메모리에 저장한다.
- 그리고 agent는 network를 메모리에 있는 로그에 따라 업데이트하게 된다.
Agent Design
- State : 큐 길이, 총 차량 수, 차량 별의 기다리는 시간, 차량의 위치를 담고 있는 이미지와 현재 신호 상태와 다음 신호 상태
- Action : a = 1이면 신호 변경, a = 0이면 신호 유지
- Reward : action 후 queue의 길이(L), 레인별 주행 지연 시간(D), 모든 레인에 있는 차량의 대기시간(W)…등등등을 합산한 값(아래 식을 참고)
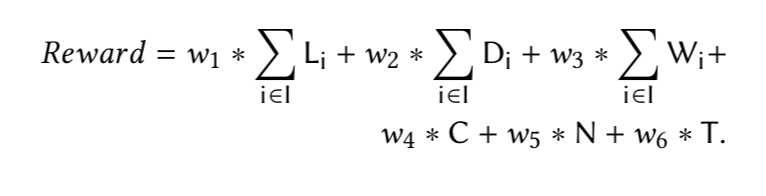
- 결국 우리 Agent의 미션은 더 많은 리워드를 얻을 수 있는 액션을 취하는 것이다.
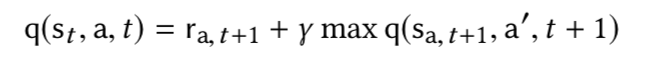
Network Structure
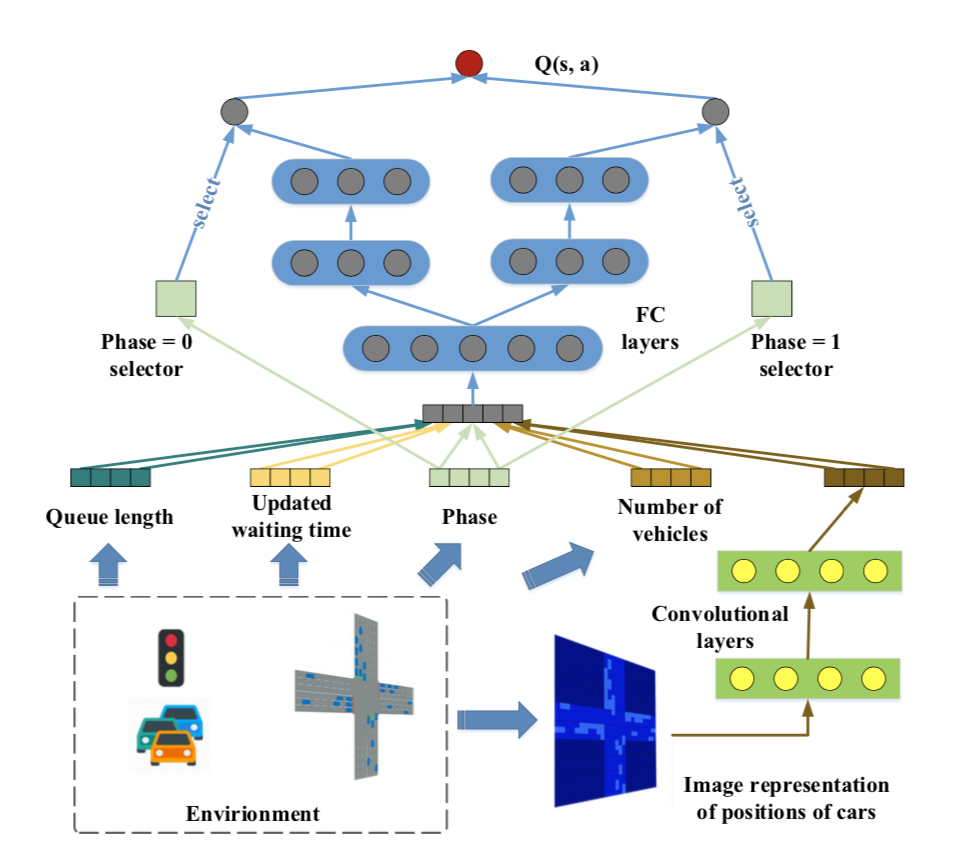
- 이제 agent는 미션을 이루기 위해 Deep Q-Network Q(s,a)를 배우게 될 것이다.
- 첫 단계는 교통 상황에 따라 partial reward를 제공한다. 이거는 모든 phase와 공유하고,
- 그리고 액션을 고르기 위해 agent는 현 상황에서 각 phase의 신호를 주고 나서 action을 취한 결과를 Q-function에 전달한다.
- 이때 각 phase는 phase 별로 explicit하게 진행되어야 한다.
- 이렇게 학습할 수 있도록 도와주는 것이 phase selector와 phase gate의 역할이다.
- 이 게이트를 통해 각 phase의 학습 과정이 서로에게 영향을 미치지 않을 수 있도록 도와준다.
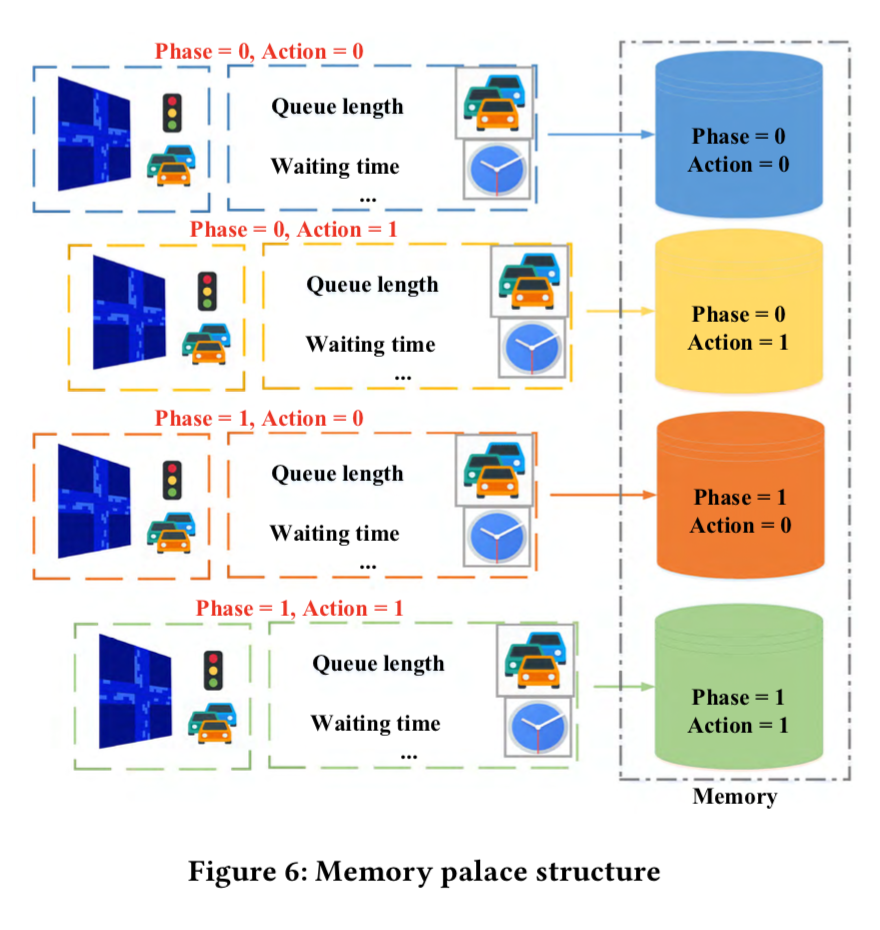
Memory Palace and Model Updating
- agent는 이제 주기적으로 memory로부터 sample을 가져오고 network를 업데이트하는데 사용한다.
- replay memory는 가끔 오래된 샘플을 새로운 샘플로 대체하기도 한다.
- 과거 알고리즘은 샘플을 한 군데 모아놓았다.
- 이 때, 불균형적인 setting에서 학습을 진행하게 되면 자주 등장하는 phase와 action이 전체를 지배하게 하는 상황을 초래한다.
- 그러면 결국 agent는 자주 등장하는 phase와 action을 선택하게 된다.
- 그러므로 각 레인에 신호가 다르게 주어졌을 때, 불균형적인 sample이 성능 저하를 초래하게 된다.
- 이를 위해서 sample을 phase와 action에 따라 각각의 memory palace에 따로 저장한다.
- agent는 각 palace에서 같은 수의 sample을 취해서 더 정확하게 reward를 예측할 수 있게 돕는다.
Experiment
- 실험은 SUMO라는 simulation platform을 이용하였다.
- 실험은 synthetic data와 real-worl data를 이용해서 진행하였다.
- synthetic data는 4거리로 2개의 phase로 구성하였다.
- Green-WE : 동서 green, 남북 red, Red-WE : 동서 red, 남북 green
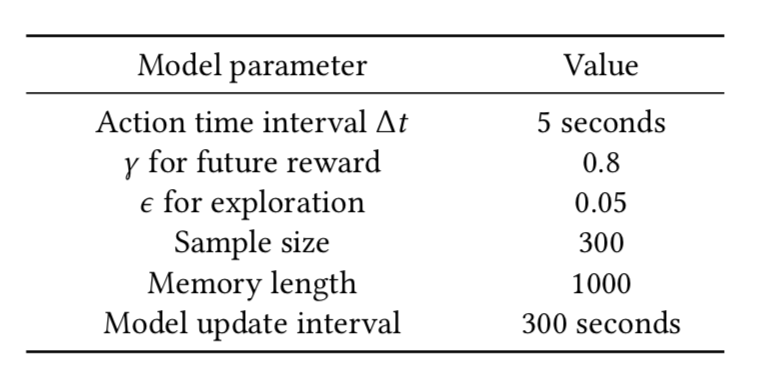
- 우리가 사용하였던 모델의 parameter는 아래와 같다.
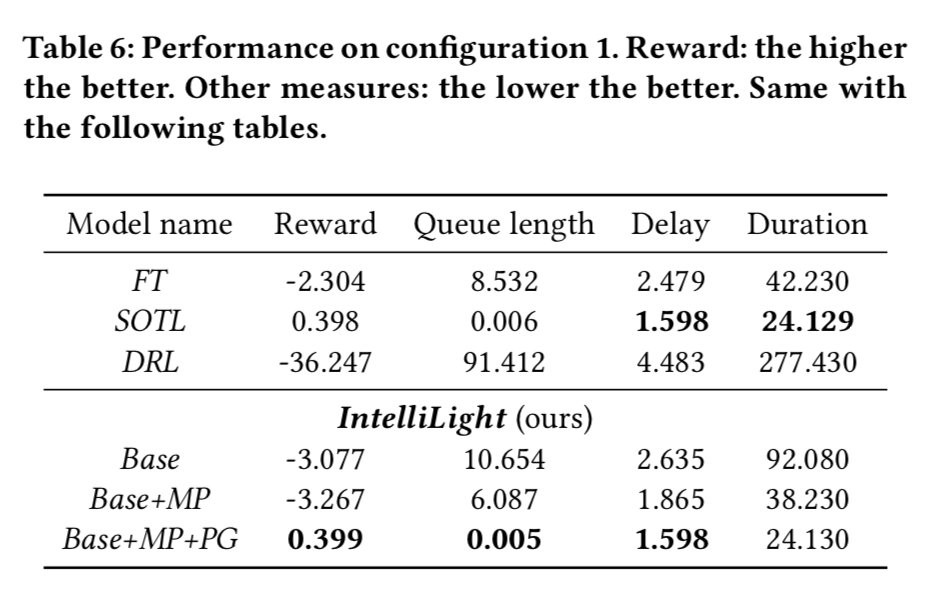
- 아래와 같이 기존 intellilight에 MP(memory palace)와 PG(Phase Gate)를 사용했을 때의 결과가 가장 좋은 것을 볼 수 있었다.
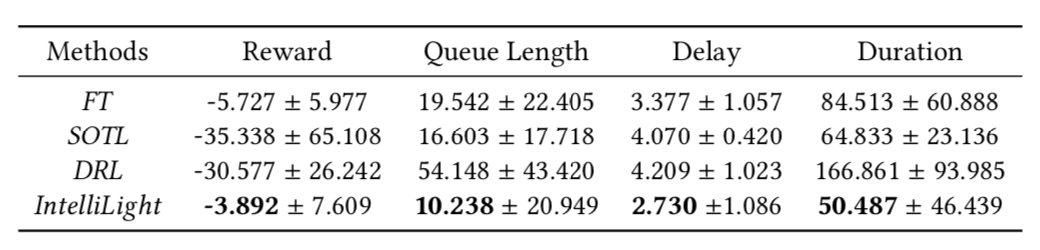
Performance on Real-world Data
- 실제 환경에서도 다른 방법들과 비교했을 때 더 많은 reward를 얻는 것으로 확인되었다.
- 그리고 실제 교통 상황에 따른 관찰 결과는 다음과 같다.
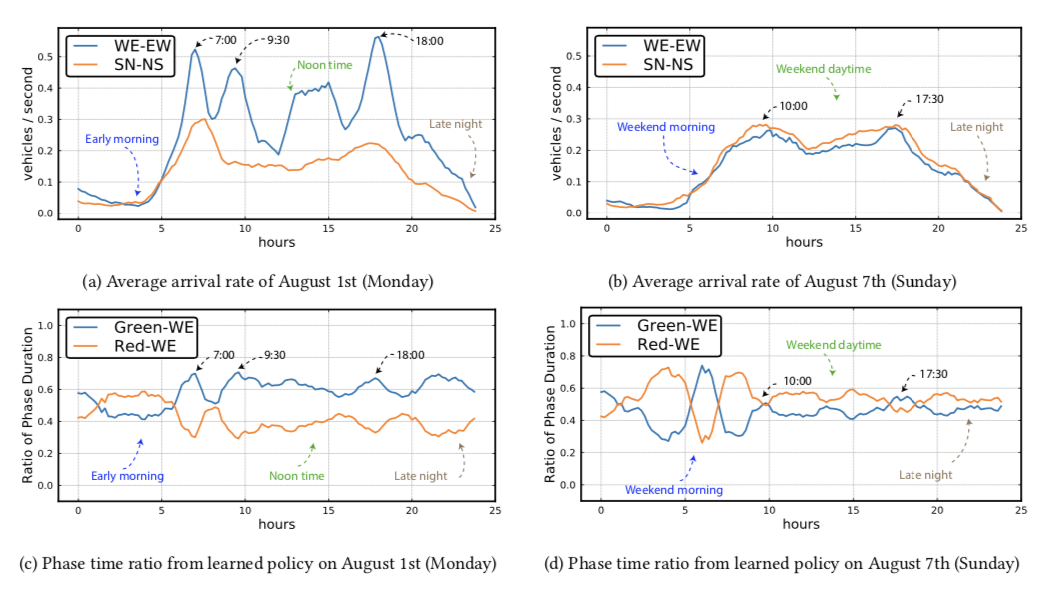
- 위의 그림에서 볼 수 있드시 월요일 7시, 9시반, 18시쯤에 WE에 차량수가 늘어나자 자연스럽게 WE에 초록불이 더 오래 켜져있는 것을 볼 수 있다.
- 주말에는 주중과 확연히 다른 교통량을 확인할 수 있었다. 낮시간 동안 SN의 차량수가 WE보다 살짝 많기 때문에 신호시간도 이에 맞춰서 반응하는 것을 볼 수 있다.
이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다.
Subscribe via RSS