
(TrafficJAM) 교통제어 강화학습 논문 정리 - Diagnoising Reinforcement Learning for Traffic Signal Control by Guanjie Zheng (2019)
by 줌코딩
요약 목적
- 이 자료는 개인 프로젝트를 진행하기 위함이라 강화학습 쪽으로 많이 편중될 수 있음을 참고하길 바란다.
Abstract
- 이 논문은 reinforcement learning(RL)을 traffic signal control에 적용시키는데 있어서 가자 중요한 부분인 reward와 state 설정을 어떻게 할 것인가에 대한 solution과 이를 기반으로 classic transportation theory에 RL을 적용시키는 방안(LIT)을 제안하고 있다.
Introduction
Setting the Reward
- 교통신호 시스템 제어의 궁극적인 목표는 신호를 최적화하는 것이 아니라 각 차량의 주행시간을 최소화 하는 것이다.
- 주행시간에 영향을 미치는 것은 신호 뿐 아니라 여러 요인들이 존재한다.
- 이를 위해 기존 연구들은 queue length, waiting time, number of switches in traffic signal, total delay 등을 복합적으로 이용해서 reward를 표현하였다.
- 여기서 문제는 이렇게 최적화한 reward가 주행시간을 최적화하는지에 대한 확신이 없다.
- 아래 figure 1은 reward 설정에 따른 주행시간의 추이를 실험한 결과이다.
- 이는 reward에 특징을 추가하는 것이 주행시간을 최적화하지 않음을 보여준다.
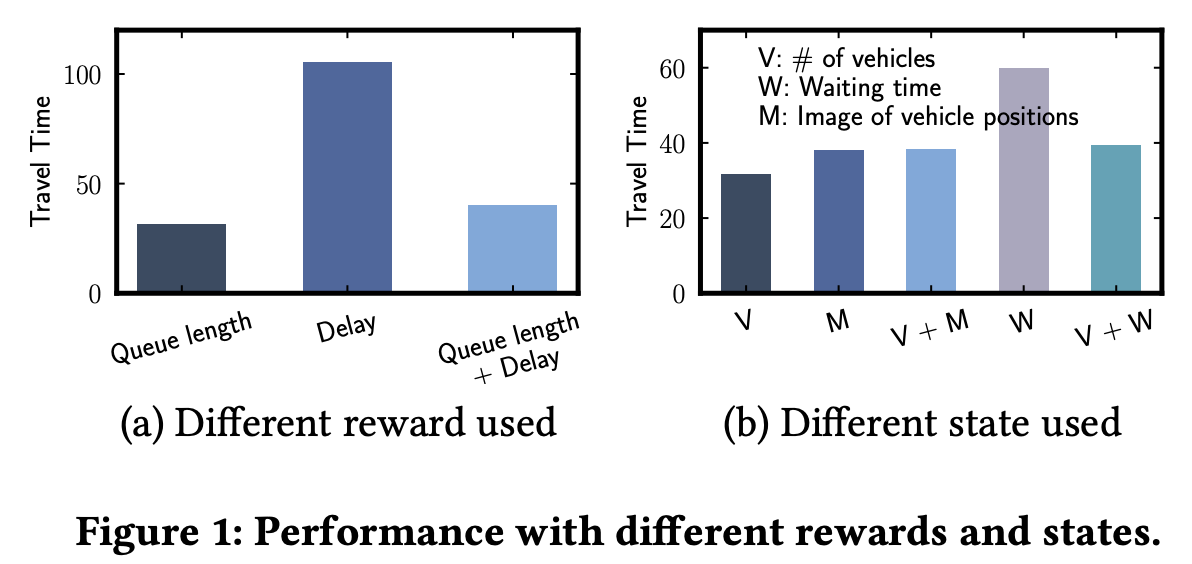
- 실험에서 보이듯이 reward를 queue length로 설정하는 것이 제일 좋은 주행시간을 낸다.
- 이 논문에서는 queue length의 최적화가 주행시간의 최적화라는 것은 앞으로 증명될 예정이다.
Setting the State
- 요즘 교통 제어 RL의 추세는 state에 더 많은 feature을 추가해서 학습하는 것이다.
- 때론 이미지를 state에 추가해서 학습하기도 한다.
- 하지만 이는 오히려 agent가 학습하는데 시간을 늘리게 되고, 학습시간이 늘어나는 것이 significant performance gain을 가져다 주지는 않는다.
- 이 논문에서는 교통 제어 RL의 state는 차량수(number of vehicles)와 현재 교통 신호(current traffic signal phase)면 충분하다는 것을 보일 것이다.
Problem definition
Preliminary
- Entering Direction : 4방향(E, W, N, S)
- Signal Phase : 두개만 초록불로 표현 할 것이다. ex) WT-ET : 서쪽 초록, 동쪽 초록, 나머지 빨간
RL Environment
- RL Environment란 현재 교차로의 상태를 보여준다.
- Agent는 현재 환경을 관찰하고 이를 state($s_t$)로 표현한다.
- 그리고 미리 만들어 놓은 signal phase order를 agent에게 제공한다.
- agent는 timestamp 마다 신호를 바꿀지 말지를 결정하고 action($a_t$)을 취한다.
- 여기서 action을 취하고 나면 state는 $s_{t+1}$로 변하게 되고 이에 따른 reward($r$)이 주어지게 된다.
- reward는 $R(s_t,a_t)$로 state에서 action을 취했을 때 주어지는 보상을 의미한다.
- Problem Definition은 한다.
Problem 1. state의 set인 S와 action의 set인 A, Reward function이 주어졌을 때 각 state에 최대의 discounted reward 반환하는 최적의 action을 찾는 policy를 찾아라!
- 반환값을 위한 공식은 다음과 같다.(미래의 값에는 적당한 $\Gamma$를 곱해준다.)
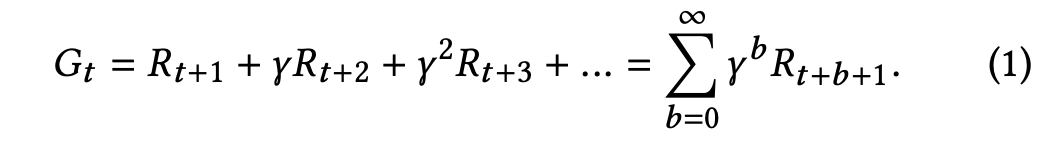
State, Action, Reward Definition
\[R_t = -\sum_{j=1}^M q_{t,j}\]
- state : number of vehicles on each lane j($v_{j,t}$), the current signal phase $p_t$
- action : 신호가 바뀌는 거면 $a_t = 1$, 아니면 $a_t = 0$
- rewards : 모든 lane의 queue 길이의 합(합이 작은 경우가 좋은 것이기 때문에 음수를 취한다.)
Objective
- 이 논문의 목표는 위의 문제를 해결하는 RL 알고리즘을 찾고
- 이를 classic transportation theory랑 연결시켜서 state와 reward 정의가 잘됐다는 걸 증명하고
- 실제로 다른 논문들보다 잘하는지 증명하는 것이다.
Method
- RL에 대해 잘 모르고 막 적용을 하는 사람이 늘다보니까 state와 reward가 redundant한 경우가 상당히 많고 불필요한 것들이 마구 들어가 있다..(자신감 뿜뿜)
- 이 논문은 필요한 애들만 있는 simple한 RL 모델을 소개한다.
Sketch of Our RL Method
- 우리 알고리즘은 앞서 설명한 reward와 state를 이용할 것이다.
- 강화학습 알고리즘으로는 DQN 알고리즘을 사용할 예정이다.
- state는 아래 그림과 같이 차량 수에 대한 정보와 현재 신호에 대한 정보가 더해져서 구성될 것이다.
- reward는 action을 취한 후에 주어지는 모든 -(queue의 길이의 합)으로 표현할 수 있다.
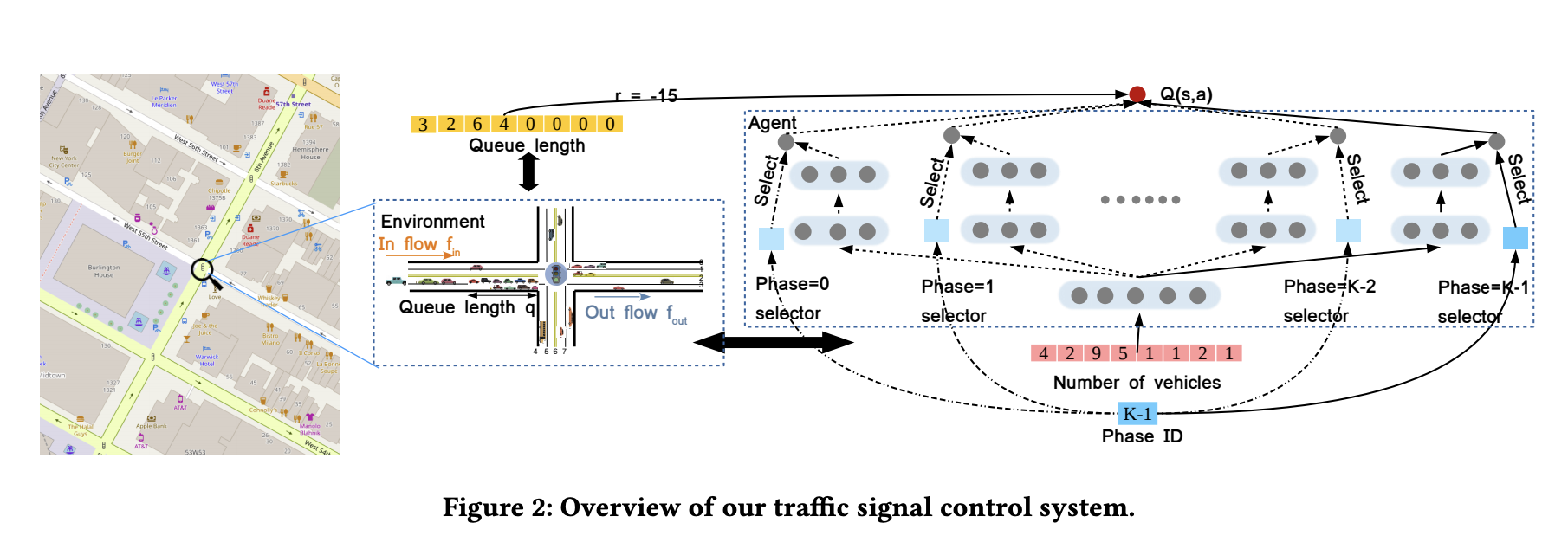
Connecting RL with Transportation Theory
- reward는 queue length로, state는 레인별 차량 수와 현재 신호로 여길 것이다.
Reward Proof
- 0부터 일정시간 동안 M개 레인의 큐의 개수를 모두 더한 값이 가장 작게 하는 policy를 우리의 목표이다.
- 즉 아래 공식과 같이 표현할 수 있고, 이는 $\tau$까지의 시간동안 각 큐가 가지는 시간당 평균 길이이다.
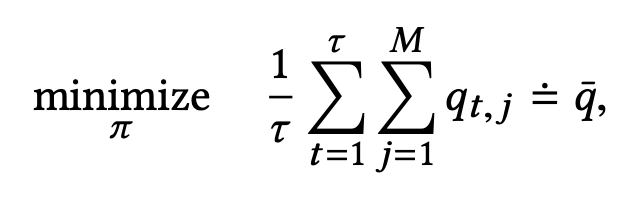
\[e_t = sum_{j=1}^M q_{t,j}\]
- 그리고 각 시간 대 별로 대기하고 있는 차량의 수를 $e_t$라고 했을 때 이는 각 시간 대에 큐에 있는 차량의 수로 표현 할 수 있다.
- 그렇다면 총 대기시간(W)는 $\tau$까지의 시간 동안의 모든 $e_t$의 합으로 표현할 수 있고 이는 결국 $\tau$(시간)* 총 q 길이의 평균으로 표현할 수 있다.
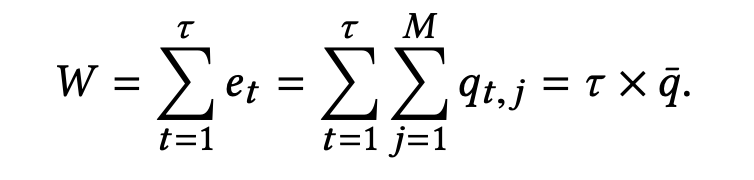
\[D_i = sum_{t=1}^\tau q_{t,i}\]
- 이것을 각 차량이 교차로를 통과하는데 추가로 필요한 시간 Delay(D)는 다음과 같이 나타낼 수 있다.
- 위의 식들을 기반으로 모든 차량의 평균 주행시간을 식으로 표현하면 다음과 같다.
- 여기서 $l/\mu$는 총 이동거리/속도를 나타낸다.
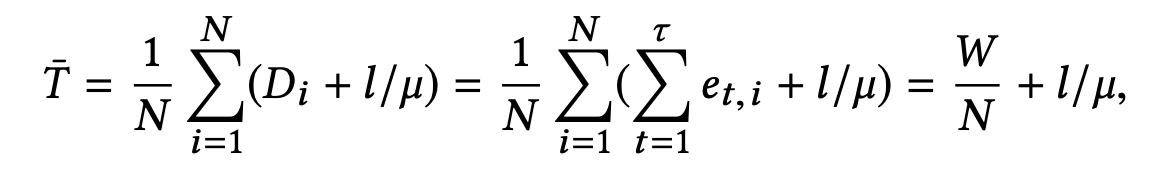
- 결국 평균 주행거리는 평균 queue의 길이와 비례함을 볼 수 있다.
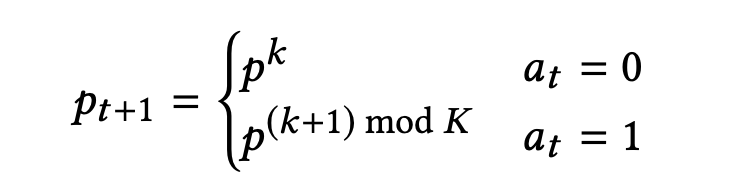
- 이는 queue의 길이를 감소시키면 주행거리가 감소될 것임을 증명한다.
State Proof
\[v_{t+1,j} = v_{t,j} + f_{in,j} - f_{out,j} * c_{t,j}\]
- state를 설명하는데 있어도 각 레인의 차량수와 현재 신호 상태만 있다면 state를 충분히 표현할 수 있다.
- 현재 시간에서의 신호($p_t$)를 $p^k$라고 하면 다음 시간에서의 각 레인의 차량수는 다음과 같이 표현 가능하다.
- 여기서 t 시간에 j 레인이 빨간불이라면 $c_{t,j}$ 는 0이고 초록불이면 1이다.
- 즉 원래 대기하고 있던 차량($v_{t,j}$)에 새로 들어온 차량($f_{in,j}$)에다가 신호가 바뀌었다면 나간 빠져나간 차량의 수($f_{out,j} * c_{t,j}$)를 빼준 것이 $t+1$의 챠량의 수이다.
- 이 때, 다음 신호는 다음과 같이 표현 할 수 있다.
- 신호가 바뀌었다면($a_t = 1$) 다음 신호 상태로 아니라면 현재와 동일한 $p^k$로 한다.
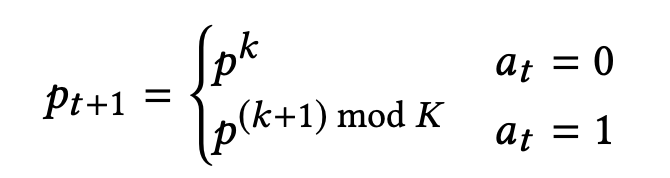
- 이를 통해 빨간불일 때의 $f_in$은 $f_{in,j} = v_{t+1,j} - v_{t,j}$로 초록불일 때의 $f_out$은 $f_{out,j} = v_{t,j} - v_{t+1,j} + f_{in,j}$로 표현할 수 있다.
- 때문에 이론적으로 환경의 현재 상태는 $v_j$와 $p$만으로 표현이 가능하다.
Analysis of Traits of RL Approach
- RL을 이용해서 얻을 수 있는 장점 3가지를 설명하고 있다.
- Online learning : 실시간으로 배우고 업데이트 한다.
- Sampling guidance : 과거에 reward가 높았던 학습 경험을 기반으로 행동한다.
- Forecast : Q-function을 이용해서 미래의 reward를 예측할 수 있다.
Experiments
Experiment Setting
- SUMO라는 교통 simulator를 사용하여 다른 모델과 비교를 진행하였다.
- SUMO에서 state를 제공받으면 그에 따라 신호체계를 변경하였다.
- 각 차량의 travel time을 기준으로 비교하였다.
- 일단 중국의 두도시(City A, B)와 LA의 실제 교통환경을 배경으로 실험을 진행한 결과 LIT가 확연히 빠른 것을 볼 수 있다.
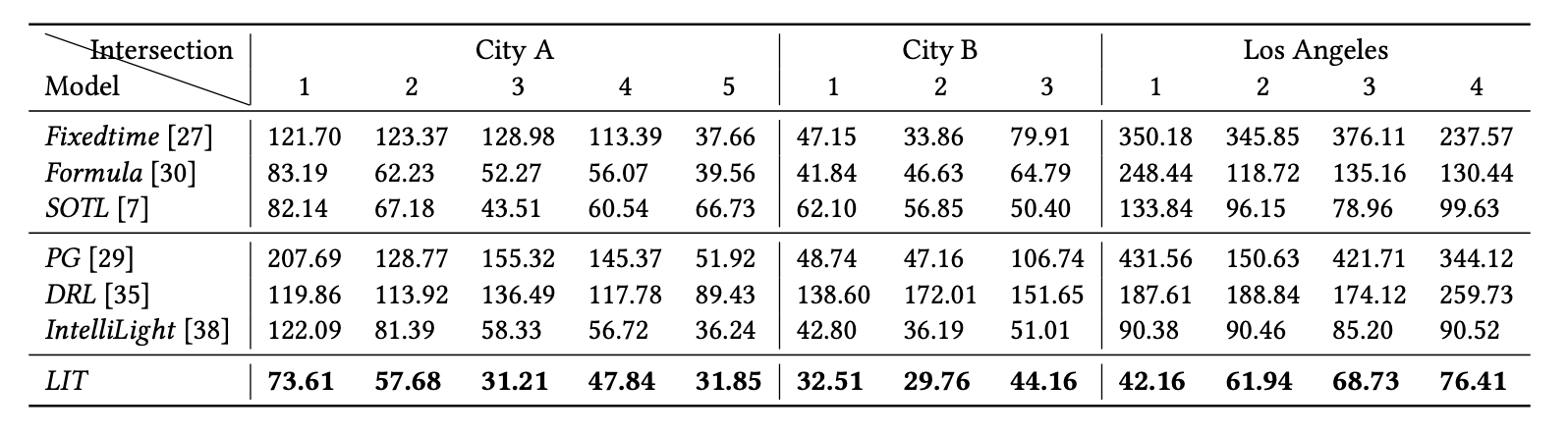
- Uniform Traffic에서도 확연히 나은 모습을 볼 수 있었으며,
- Multi intersection 환경에서도 월등한 성과가 있었다.
Conclusion
- LIT is good!
- Simple is the Best!
Reference
Guanjie Zheng, Xinshi Zang, Nan Xu, and Hua Wei. 2019. Diagnosing Reinforcement Learning for Traffic Signal Control
느낀점
- 일단 RL을 적용해보는 것은 처음이라 걱정했는데 일단 여기서 말하는 대로 state와 reward에 대한 정의는 간단하게 해도 된다고 하니 일단은 다행이다.
- intelliLight에서 발전된 논문으로 intelliLight에 대한 논문(Intelligent Traffic Signal Control: Using Reinforcement Learning with Partial Detection) 또한 읽어 볼 필요가 있을 것 같다.
이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다.
Subscribe via RSS