
(OS 기본개념 정리) CH5 Process Scheduling
by 줌코딩
Chapter5. Process Scheduling
5.1 Basic Concepts
프로세스 스케쥴링의 목적은 CPU가 쉬지않고 일하게 하는게 뽀인트이다.
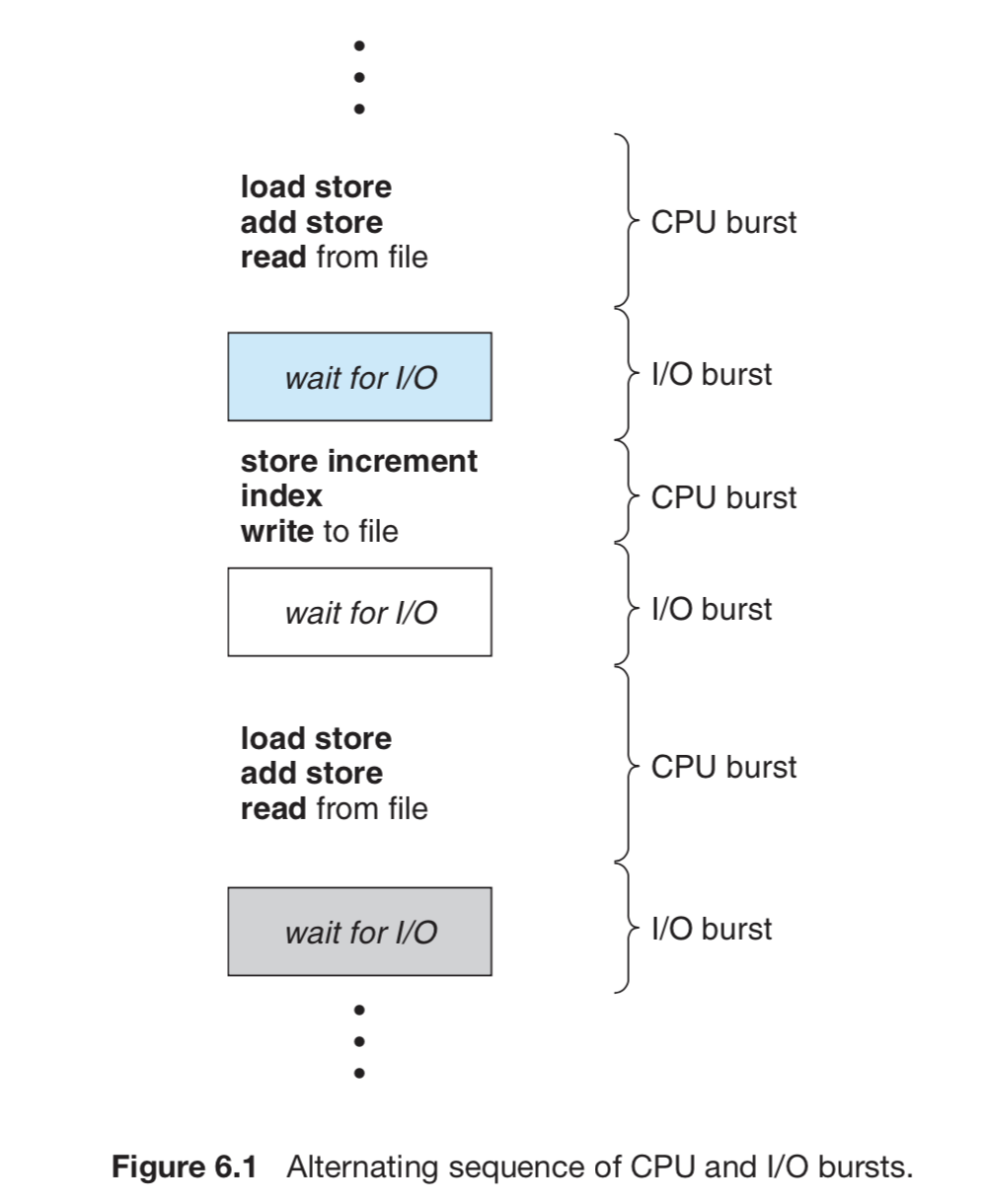
Process가 CPU burst와 I/O wait 하는 cycle을 반복하는데 이것을 반영한 scheduling이 중요하다.
CPU Scheduler
short term scheduler에 의해 프로세스가 선택된다.
Preemptive Scheduling
- child node가 끝나길 기다린다.(running to waiting)
- interrupt가 발생한다.(running to ready)
- IO가 끝날 때 까지 기다렸다가 돌아온다.(waiting to running)
- process를 종료한다.
1번과 4번은 scheduling이 필요하지않다. 하지만 2번과 3번은 scheduling이 매우 필요하다. preemtive : 선취하다 앞지르다.
Dispatcher
CPU의 Control을 다른 process에게 전달해주는 역할을 하는 모듈이다.
역할은 크게
- Context Switching
- Switching to user mode
- Jumping to the proper location in the user program to restart that program
이 때 프로세스 하나를 멈추고 새로운 프로세스를 시작하는데 까지 걸리는 시간을 dispatch latency라고 부른다.
5.2 Scheduling criteria
- CPU Utilization : CPU를 최대한 바쁘게 해야해
- Throughput : 시간당 프로세스 처리량을 최대한으로
- Turnaround Time : 내 턴이 돌아오는데 걸리는 시간을 최소로(Cool Down 시간)
- Waiting Time : Ready Queue에서 기다리는 시간을 최소로
- Response Time : request에 대한 결과를 최대한 빨리 전달
즉, CPU Utilization, throughput 최대로, Turnaround Time, Waiting Time, Response Time 최소로
5.3 Scheduling Algorithms
First Come First Serve Scheduling
- FIFO 형식 구현, 이해 쉬움
- 대기 시간이 보통 길다.
- IO나 Terminate할 때까지 CPU를 가지고 있는다.(NON-PREEMPTIVE)
- 즉각적으로 반응해줘야하는 interrupt 같은 친구들 대응 힘들어

Shortest Job First Scheduling
- SJF는 Job중에서 CPU burst가 가장 짧은 친구를 먼저 선택한다.
- average waiting time 은 optimal하다.
- 근데 다른 process의 CPU time을 모르므로 예측샷을 때린다.
- 예측샷 : 이전 것들이랑 배교해서(exponential average of previous CPU bursts)
- 바로 직전꺼 CPU Burst + 바로 직전꺼 예측샷 (두개에 가중치를 정해서 더해줌)
- Preemptive & Nonpreemptive 둘다 가능


Priority Scheduling
- 우선순위를 정해줘서 프로세스를 진행한다.
- 책에서는 낮은 수가 high priority를 가지는 것으로 되어있다.
- prioriy를 측정하는 방법은 두가지이다.
- Internal : time limit, memory required
- external : OS 밖에서 정해진 것으로 중요도, fund, political factors
- preempt 가능하다.
- indefinite blocking이라는 우선순위 낮은 친구는 아예 수행이 계속 안될 수도 있다.
- 이를 해결하기 위해서 aging을 통해 시간이 지남에 따라 priority를 높여준다.
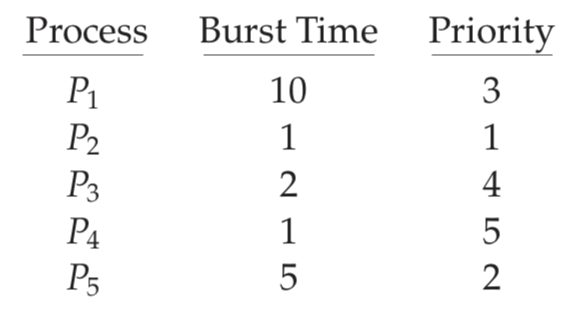

Round-Robin Scheduling
- RR은 Time sharing System이다.
- FCFS랑 유사한데 preempt를 가능하게 한 것이다.
- Time quantum을 설정해서 이 단위 만큼 일을 수행할 수 있도록 한다.
- Time quantum마다 interrupt를 날려서 실행 시간이 퀀텀보다 작으면 process release
- 아니면 하던 일을 다시 queue에 집어 넣어
- quantum size를 잘 설정해줘야 한다. 왜냐하면 엄청 작으면 실행하는 내내 context switching이 너무 costy해
- 때문에 큐에 있는 친구들의 CPU burst의 80% 이내가 Time quantum 안에 들어와야 한다.


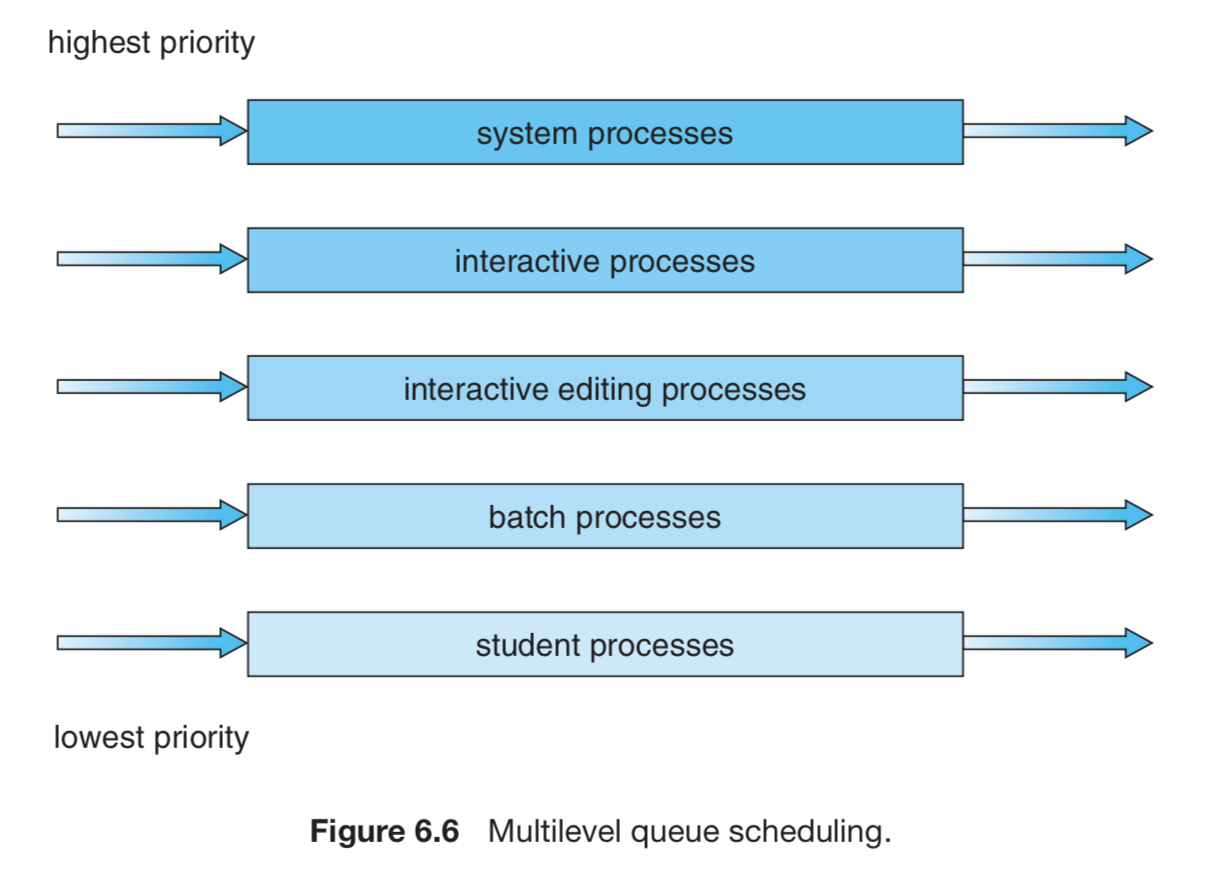
Multilevel Queue Scheduling
- 프로세스를 여러 그룹으로 구분 가능할 때(foregroud, background)
- queue를 여러개로 쪼개고 각자의 algorithm을 적용한다.
- queue를 scheduling해 (priority setting) 후 순서대로 확인한다.
Summary
CPU scheduling is the task of selecting a waiting process from the ready queue and allocating the CPU to it. The CPU is allocated to the selected process by the dispatcher.
First-come, first-served (FCFS) scheduling is the simplest scheduling algo- rithm, but it can cause short processes to wait for very long processes. Shortest- job-first (SJF) scheduling is provably optimal, providing the shortest average waiting time. Implementing SJF scheduling is difficult, however, because pre- dicting the length of the next CPU burst is difficult. The SJF algorithm is a special case of the general priority scheduling algorithm, which simply allocates the CPU to the highest-priority process. Both priority and SJF scheduling may suffer from starvation. Aging is a technique to prevent starvation.
Round-robin (RR) scheduling is more appropriate for a time-shared (inter- active) system. RR scheduling allocates the CPU to the first process in the ready queue for q time units, where q is the time quantum. After q time units, if the process has not relinquished the CPU, it is preempted, and the process is put at the tail of the ready queue. The major problem is the selection of the time quantum. If the quantum is too large, RR scheduling degenerates to FCFS scheduling. If the quantum is too small, scheduling overhead in the form of context-switch time becomes excessive.
The FCFS algorithm is nonpreemptive; the RR algorithm is preemptive. The SJF and priority algorithms may be either preemptive or nonpreemptive.
Multilevel queue algorithms allow different algorithms to be used for different classes of processes. The most common model includes a foreground interactive queue that uses RR scheduling and a background batch queue that uses FCFS scheduling. Multilevel feedback queues allow processes to move from one queue to another.
Many contemporary computer systems support multiple processors and allow each processor to schedule itself independently. Typically, each processor maintains its own private queue of processes (or threads), all of which are available to run. Additional issues related to multiprocessor scheduling include processor affinity, load balancing, and multicore processing.
A real-time computer system requires that results arrive within a deadline period; results arriving after the deadline has passed are useless. Hard real-time systems must guarantee that real-time tasks are serviced within their deadline periods. Soft real-time systems are less restrictive, assigning real-time tasks higher scheduling priority than other tasks.
Real-time scheduling algorithms include rate-monotonic and earliest- deadline-first scheduling. Rate-monotonic scheduling assigns tasks that require the CPU more often a higher priority than tasks that require the CPU less often. Earliest-deadline-first scheduling assigns priority according to upcoming deadlines—the earlier the deadline, the higher the priority. Proportional share scheduling divides up processor time into shares and assigning each process a number of shares, thus guaranteeing each process a proportional share of CPU time. The POSIX Pthread API provides various features for scheduling real-time threads as well.
Operating systems supporting threads at the kernel level must schedule threads—not processes—for execution. This is the case with Solaris and Windows. Both of these systems schedule threads using preemptive, priority- based scheduling algorithms, including support for real-time threads. The Linux process scheduler uses a priority-based algorithm with real-time support as well. The scheduling algorithms for these three operating systems typically favor interactive over CPU-bound processes.
The wide variety of scheduling algorithms demands that we have methods to select among algorithms. Analytic methods use mathematical analysis to determine the performance of an algorithm. Simulation methods determine performance by imitating the scheduling algorithm on a “representative” sample of processes and computing the resulting performance. However, simulation can at best provide an approximation of actual system performance. The only reliable technique for evaluating a scheduling algorithm is to implement the algorithm on an actual system and monitor its performance in a “real-world” environment.
- Opearting System Concepts Ninth Edition by Abraham Silberschatz 참조
Subscribe via RSS