
(강화학습 입문) 4. 강화학습 심화:딥살사(Deep SALSA)
by 줌코딩
5장 강화학습 심화 1: 그리드월드와 근사함수
이번 장부터 내용이 매우 심화되어서 이해하는데 어려움을 겪었다. 내가 공부한 내용을 정리해보고자 한다.
근사함수
몬테카를로, 살사, 큐러닝의 한계
- 앞서 보았듯이 다이내믹 프로그래밍과 다르게 위 3가지 방법은 모델 프리하게 학습할 수 있다.
- 하지만 경우의 수가 우주의 원자 수보다 많은 환경에서 발생하는 계산 복잡도와 차원의 문제라는 두가지 큰 문제는 해결할 수 없다.
- 이를 위해 큐함수를 테이블이 아닌 매개변수로 근사화 함으로 이를 해결했다.
근사함수를 통한 가치함수의 매개변수화
- 무수히 많은 점이 있는 그래프에서 정확하지는 않지만 위의 점들을 근사할 수 있는 함수를 만들어 낼 수 있다면 이는 매우 효율적일 것이다.
- 이러한 함수를 근사함수라 부르며 가장 많이 쓰이는 근사함수는 인공신경망이다.
인공신경망
인공신경망 1: 인공신경망의 개념
- 뇌를 구성하는 신경세포인 뉴런에서 영감을 받아 만든 수학적 모델이다.
- 아래 그림과 같이 각 뉴런은 신호를 받아 신호의 임계치가 일정 수준을 넘기면 신호를 다른 뉴런에게 전달한다.
- 이를 본따서 Node를 만들었는데 노드에는 Input이 들어오며, 이는 일정한 가중치를 곱해져서 더해지게 된다.
- 이 더해진 값은 활성함수(Activation Function)을 통해 다른 노드에 전달되게 된다.
Activation Function의 input = sum of (input) * (weight) + bias
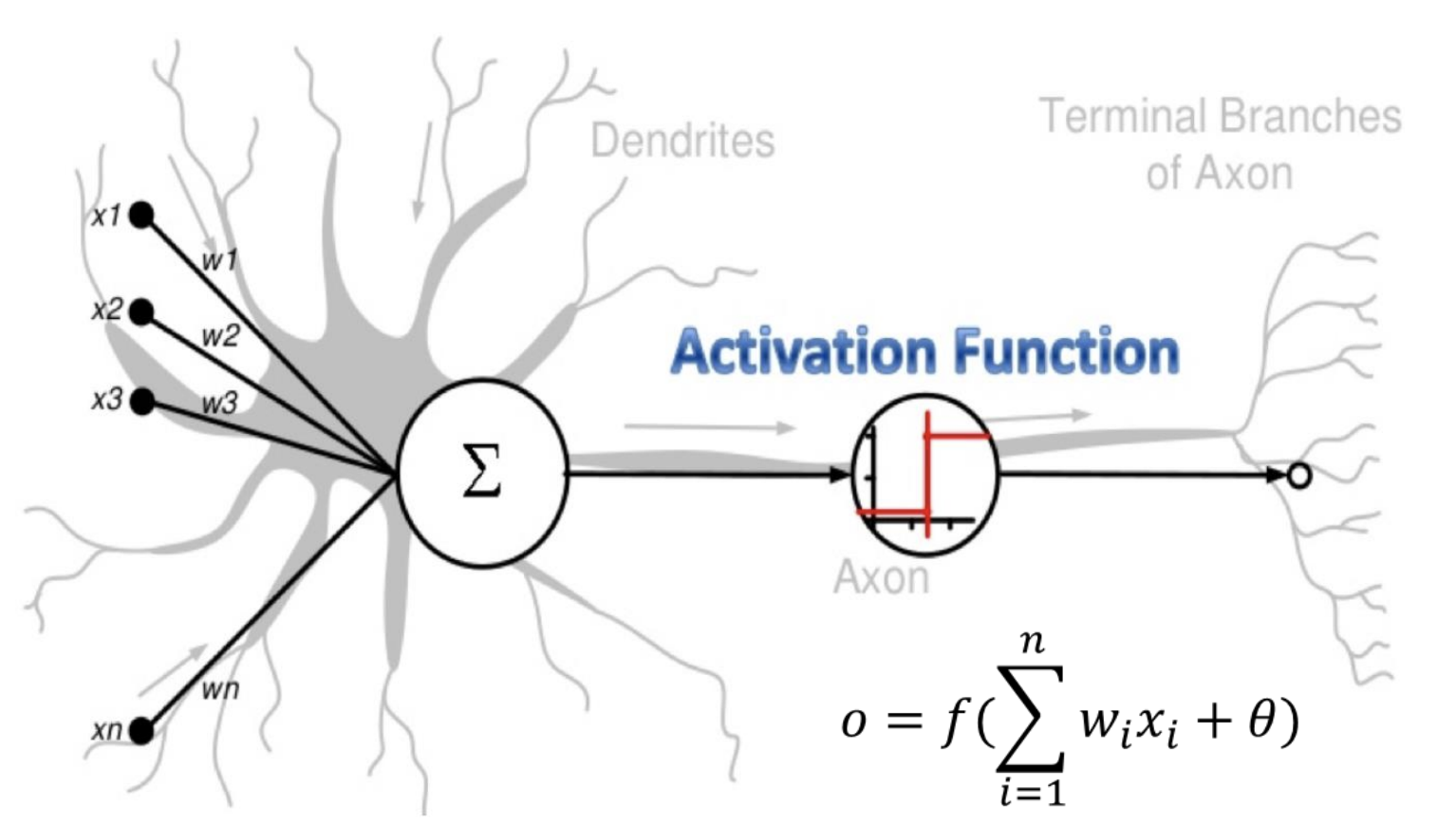
인공신경망 2: 노드와 활성함수
- 노드는 일종의 계층 구조를 만들게 되는데 아래 그림과 같이 입력층(Input Layer), 은닉층(Hidden Layer), 출력층(Output Layer)로 나눠져 있게 된다.
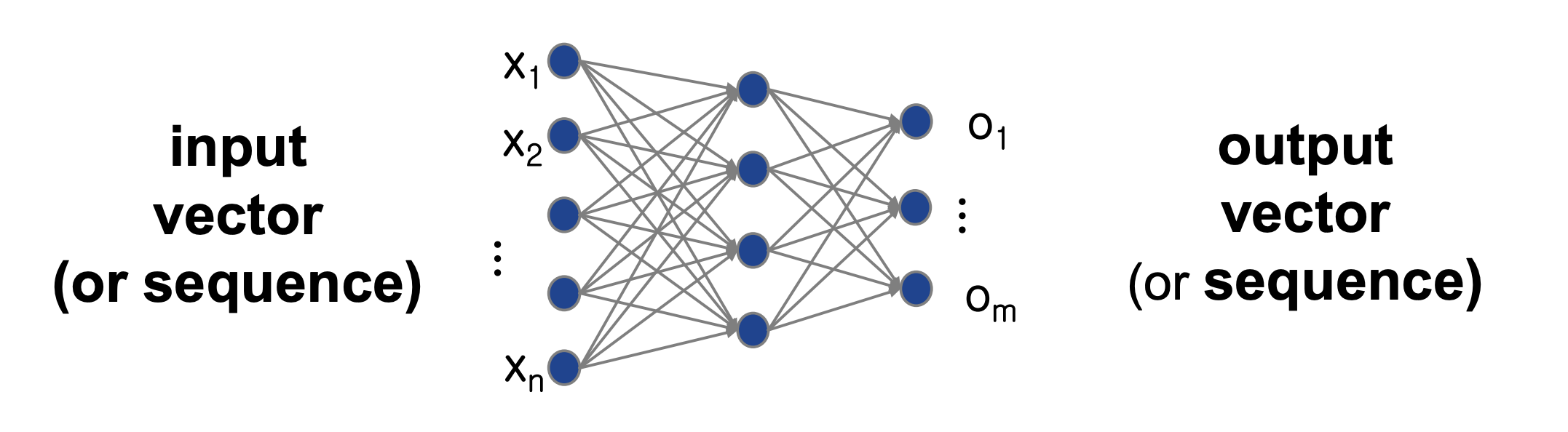
- 노드는 입력을 받아서 활성함수를 통해 다음 층으로 결과를 전달하게 되는데 인공신경망에서는 ReLU, Tanh, Sigmoid가 주로 활성함수로 쓰인다.
- 가장 대표적인 Sigmoid는 어떤값이 들어오든 출력 값을 0과 1 사이로 만들어주는 함수이다.
- ReLU는 0보다 작은 값이 들어오면 0, 0보다 큰 값들은 고대로 출력해주는 함수이다.
- 굳이 선형함수를 사용하지 않고 비선형 함수를 사용할까?
- 그 이유는 여러 층이 쌓여있다고 하더라도 선형 함수의 경우에는 층이 하나인 것과 다름이 없다. 하지만 비선형 함수인 경우 층이 쌓일 수록 함수가 새로운 형태로 변형된다.
- 이렇게 2개 이상의 은닉층을 가진 인공신경망을 심층신경망(Deep Neural Network)이라고 부른다.
인공신경망 3: 딥러닝
- 심층신경망의 장점은 알아서 인간이 어떤 특징(Feature)을 찾아주는 것이 아니라 신경망이 알아서 추상화를 통해 특징을 추출해준다는 것이다.
- 기존의 머신러닝은 특징을 사람이 의도하는 대로 추출해서 그것을 학습에 사용했다.
- 하지만 딥러닝에서는 각 노드가 각자 다른 특징을 추출한다.
인공신경망 4: 신경망의 학습
- 딥러닝에서 학습은 결국 weight(가중치)와 bias(편향)을 학습하는 것이다.
- 입력이 심층 신경망을 통과해서 나온 출력을 예측이라고 한다.
- 이 출력이 다가가야하는 정답을 타깃이라고 하는데 이 타깃과 출력의 오차를 계산해야 한다.
- 그 역할을 하는 것이 Loss Function(오차함수)이다.
- 대표적인 오차함수로는 Mean Square Error(MSE)가 있다.
- 이 함수에서 오차는 (타깃 - 예측)^2으로 나타낼 수 있다.
- 이처럼 발견된 오차를 최소화하도록 심층신경망의 가중치와 편향을 업데이트 해주는 과정을 학습이라고 한다.
어떻게 편향과 가중치를 업데이트 할까?
- Back-Propagation(역전파) 알고리즘을 이용하면 이것이 가능하다.
- 오차를 계산한 후에 각 노드의 가중치와 편향이 오차에 기여한 바를 계산해서 업데이트 시켜준다.
- 즉, 업데이트 값은 오차 * 오차 기여도에 비례한다.
그렇다면 오차 기여도는 어떻게 구하나?
- 오차 기여도는 오차에 대한 편미분값으로 계산한다….
- 편미분값이란 각 가중치 혹은 편향을 조금 증가시키거나 감소시켰을 때 오차가 어떻게 변하는지를 수치로 표현한 것이다.
- 즉, 편미분값을 통해 얻을 수 있는 정보는 오차를 최소화하기 위해 가중치나 편향을 증가시켜야하는지 감소시켜야하는지이다.
- 대표적인 업데이트 방법으로는 Gradient descent(경사 하강법)가 있다.
- 경사하강법에는 SGD, RMSprop, Adam과 같은 방법이 있다.
- 이들의 공통적인 특징은 한번에 얼마나 업데이트 할 것인지 결정하는 계수인 Learning Rate(학습속도)가 존재한다.
딥살사
딥살사 이론
- 만약 기존의 그리드 문제와 달리 장애물이 움직인다고 이야기해보자. 이 문제는 그냥 살사로는 풀기 어렵다.
- 이를 위해서 살사 알고리즘을 사용하되 큐함수를 인공신경망으로 근사할 수 있다.
큐함수 까먹은 나를 위해서 다시 짚고 넘어간다.
큐함수란 상태 s에서 행동 a를 했을 때 얻게되는 반환값의 기대값이다.
- 이 큐함수를 인공신경망으로 근사하는 알고리즘을 DeepSALSA(딥살사)라고 한다.
- 또 이 인공신경망을 업데이트할 때는 경사하강법을 사용한다.
- 경사하강법을 이용하려면 오차함수를 정의해야하는데 오차함수는 살사의 큐함수 업데이트식에서 가져올 수 있다.
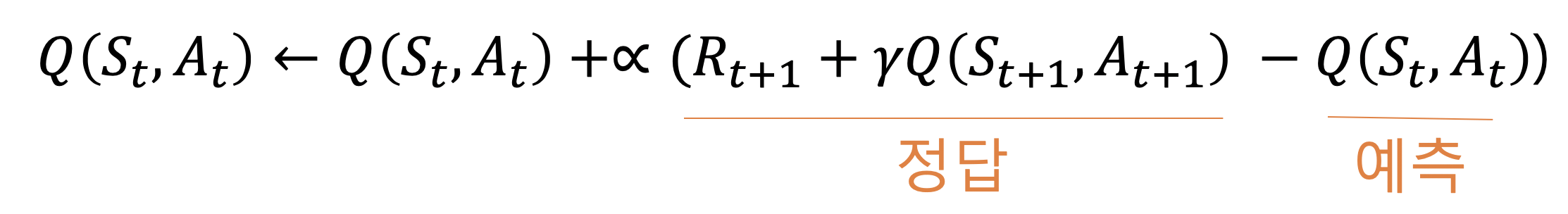
- 큐함수를 업데이트할 때는 원하는 결과인 “정답”과 현재 큐함수를 “예측”한 것과의 오차를 계산해서 곱해주게 되는데 이를 이용해서 오차함수를 만들 수 있다.
- 결국 딥살사에서의 오차함수는 다음과 같다.
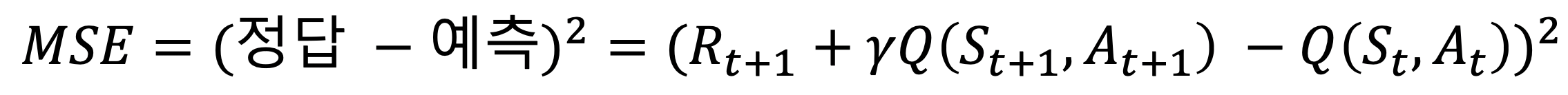
딥살사 코드 설명
그럼 이제 본격적으로 코드를 분석해보자.
- 기존 살사는 현재 상태에서 각 행동에 대한 큐함수를 가져오면 탐욕 정책으로 행동을 선택한다.
- 하지만 딥살사에서는 큐함수 테이블 대신 인공신경망을 사용한다
- 각 상태가 입력으로 들어가면 각 행동에 대한 큐함수인 인공신경망 모델이 출력된다.
인공 신경망을 생성하는 함수의 코드는 다음과 같다.
def build_model(self):
model = Sequential()
model.add(Dense(30, input_dim=self.state_size, activation='relu'))
model.add(Dense(30, activation='relu'))
model.add(Dense(self.action_size, activation='linear'))
model.summary()
model.compile(loss='mse', optimizer=Adam(lr=self.learning_rate))
return model
- sequential 모델을 생성하고 모델에 여러층을 추가 했다.
- 2개의 은닉층이 존재하고 각 은닉층은 relu를 활성함수로 사용한다.
- 출력층의 활성함수가 linear인 이유는 큐함수의 값이 0과 1 사이가 아니기 때문이다.
- 오차함수는 mse를 사용한다.
- 위 함수는 에이전트 생성시 한번 호출되어 model이라는 변수에 저장되어있는다.
self.model = self.build_model()
다음으로 액션을 가져오는 함수를 보자.
def get_action(self, state):
if np.random.rand() <= self.epsilon:
# 무작위 행동 반환
return random.randrange(self.action_size)
else:
# 모델로부터 행동 산출
state = np.float32(state)
q_values = self.model.predict(state)
return np.argmax(q_values[0])
- 이 함수는 탐욕법에 의해서 행동을 선택하게 된다.
- 무작위가 아닌 경우 모델로부터 행동을 산출해서 현재 함수에서 가장 높은 큐함수 위치를 반환하게 된다.
이번엔 모델을 학습시키는 함수를 보자.
def train_model(self, state, action, reward, next_state, next_action, done):
if self.epsilon > self.epsilon_min:
self.epsilon *= self.epsilon_decay
state = np.float32(state)
next_state = np.float32(next_state)
target = self.model.predict(state)[0]
# 살사의 큐함수 업데이트 식
if done:
target[action] = reward
else:
target[action] = (reward + self.discount_factor *
self.model.predict(next_state)[0][next_action])
# 출력 값 reshape
target = np.reshape(target, [1, 5])
# 인공신경망 업데이트
self.model.fit(state, target, epochs=1, verbose=0)
- get_action에서 사용된 epsilon은 시간이 지남에 따라 감소하게 된다.
- 그 이유는 탐험을 시간이 지남에 따라 줄이고 예측한 대로 움직이게 하기 위해서 이다.
- 각 액션의 타깃값은 동일하되 5개의 액션 중에서 실제 취한 액션에 해당하는 예측만 업데이트한다.
- model.fit을 통해서 자동으로 설정한 오류함수를 감소시키는 방향으로 인공신경망을 업데이트한다.
딥살사의 실행 및 결과
- 딥살사가 진행되는 동안 장애물은 계속해서 움직이게 된다.
- 샘플 하나인 SARSA가 진행되면 그것을 이용해서 인공신경망을 학습시킨다.
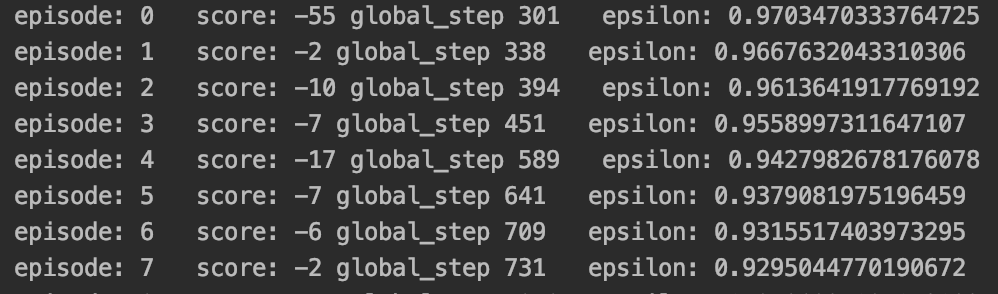
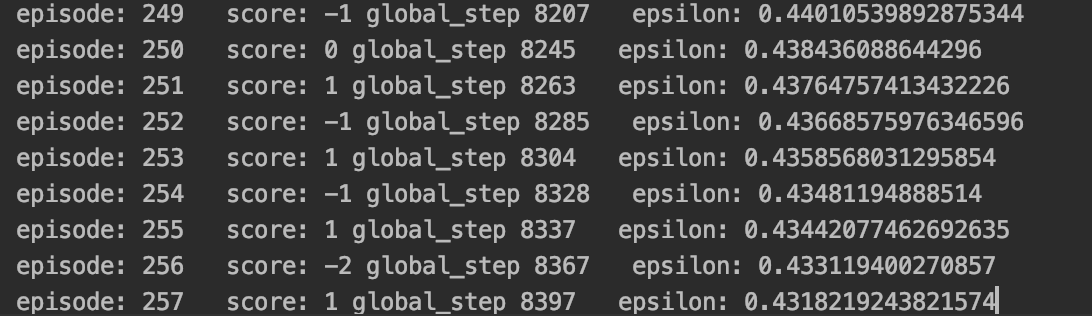
- 위의 과정을 통해서 학습된 모델은 초기에는 랜덤한 액션을 택하기에 점수가 낮을 확률이 높으나
- 점차 학습이 진행됨에 따라 점수가 높게 나오는 것을 볼 수 있다.
학습 초기!
에피소드 200이후!
나름의 정리
- 모델에 현재 상태를 넣어주면 행동 하나가 도출된다.
- 이 때 모델이 행동을 선택하는 기준은 이전과 같이 큐함수가 아닌 심층신경망에서 나온 최고의 값이다.
- 그것을 통해서 다음 상태를 구하고 이를 이용해서 다시 모델을 학습시킨다.
궁금증
- 이해가 완벽히 된 것 같지는 않다. 의문점이 생기는 것들이 있다.
- 각 은닉층의 유닛은 왜 30개이고 각 유닛의 역할은 무엇인가?
- 백트레킹은 언제하는거지?
- 이 방법의 확실한 장점은 무엇인가?
느낀점
- 엄청 적은 양의 데이터인것 같은데 어떻게 200번의 에피소드만에 발전이 있을 수 있는지 신기하다.
- 스코어가 점차 나아지는 것은 랜덤하게 가는 횟수가 줄어들어서 적어도 초록색에 부딪히면 안된다는 판단을 해서 인 것 같다.
- 200번 진행했어도 여전히 최단 경로로 이동하지는 않는 걸로 보아 그냥 초록색을 부딪히면 안된다 정도의 정보만 알고 아직은 많이 멍청한 듯하다ㅎㅎ..
- 암튼 딥러닝에 대해서 조금은 알게된 것 같아서 기분이 좋다. 여전히 완전 기초적인 질문을 하고 있는 것 같지만 그래도 오늘 완벽히 이해할 수 없을테니까 다음을 기약하면서 재밌게 하자!ㅎㅎ
이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다.
Subscribe via RSS