
(OS 기본개념 정리) CH1 컴퓨터 구조
by 줌코딩
Chapter1. Introduction
1.1 What Operating Systems Do
Computer System consists of
- hardware(CPU, memory, I/O devices)
- application programs(워드, 엑셀 등등..)
- operating system(하드웨어 컨트롤, AP를 위해 하드웨어 조정)
1.1.1 User View
Operating System design을 어떻게?
- maximize the work that the user is performing
- design은 ease of use에 따라 진행
두가지를 고려하면서 진행한다.
- resource utilization(얼마나 다양한 하드웨어, 소프트웨어 리소스가 공유되는가)
- performance(걍 성능)
예를 들어?
- single user인 경우
- share 할게 없으니 걍 performance 몰빵
- 여러 유저가 터미널로 접속하는 경우
- resource utilization이 중요
- 모바일 네트워크를 이용하는 경우
- 서버를 통해서 접속하는 경우
각 상황에 맞는 operating system 필요.
1.1.2 System View
We can view an operating system as a resource allocator.
- resource : CPU time, memory space, file-storage space, I/O devices
resource allocation is especially important where many users access the same mainframe or minicomputer.
Operating System is a control program that manages the execution of user programs to prevent errors and improper use of the computer.
1.1.3 Defining Operating Systems
How to define OS?
No firm definition.
they offer a reasonable way to solve the problem of creating a usable computing system
Common definition
The OS is one program running at all times on the computer, called Kernel
OS의 영역이 어디까지인지 확실히 정의하기 쉽지 않다. 심지어 1998년에는 MIcrosoft가 Web browser을 OS에 넣어서 OS 독점으로 고소당하기도 했다.
요즘은 OS에 여러가지가 들어가면서 모바일 OS는 Kernel + Middleware까지 포함시키고 있다.
middleware란? application developer에게 추가적인 소프트웨어 프레임워크를 제공
1.2 Computer System Organization
컴구 먼저 짚고 넘어가라
1.2.1 Computer-System Operation
Device controller가 shared memory에 대한 접근 권한을 부여한다.
To ensure orderly access to the shared memory, a memory controller synchronizes access to the memory.
예를 들어, 컴퓨터를 실행하기 위해서는 초기 프로그램이 필요(Bootstrap)
- 주로 ROM(Read only memory)이나 EEPROM과 같은 firmware에 들어있어서 시스템을 다 초기화 시켜준다.
- OS kernel을 메모리에 할당 시켜준다.
커넬 말고 부트 타임 때 메모리에 올라간 친구들을 System processes라 부른다.
이런 시스템은 이벤트를 기다리게 되는데 이벤트는 주로 interrupt에 의해 신호된다.
- 하드웨어는 CPU로 시그널 날림
- 소프트웨어는 System call로 인터럽트
만약 interrupt가 발생하면 fixed location(서비스 루틴의 시작 주소)으로 이동한 후 service routine을 실행한다. 그리고 다시 원래 computation 진행
이런 interrupt routine을 저장할 수 있는 곳이 제한되어 있기 때문에 table of pointers를 이용한다. 이 array를 Interrupt vector라고 한다.
1.2.2 Storage Structure
모든 intruction은 메모리에서 가져오기 때문에 프로그램을 실행하려면 그 정보가 메모리에 저장되어있어야 한다.
보통 RAM이라 불리는 main memory에 저장되어있는데 이는 반도체 기술인 DRAM에 실행되어있다.
ROM(변경 x) vs RAM(변경 o)  ROM에도 저장이 되는데 여기는 변경이 불가능 하기 때문에 static한 프로그램만 저장된다.
메모리는 array of byte를 가지고 있는데 각각의 byte는 그들만의 주소를 가지고 있어서 이 주소를 load하고 store하는 명령어를 실행한다. 그리고 register에 있는 정보를 메인 메모리에 store하는 식으로 진행된다.
- 전형적인 명령어(von Neumann architecture의 시스템에서 돌아가는)는 메모리에서 명령어를 가져와서 instruction register에 저장한다.
- 그 후 instruction을 디코드하고 operand를 필요하다면 fetch한다.
- 모든 operation이 끝나면 메모리에 결과 값을 저장한다.
메모리 유닛은 메모리 주소를 가지고 있지 메모리 주소가 어떻게 생성됐는지, 뭔지에는 관심을 주지 않고 메모리 주소의 sequence에만 관심이 있다.
우리는 프로그램과 데이터가 영원히 메인메모리에 존재하기 원하지만 사실 이는 2가지 이유로 불가능하다.
- 메인 메모리는 영구적으로 정보를 다 저징하기에는 너무 작다.
- 파워가 꺼지면 사라지기 때문에 volatile(변덕스러운)하다.
그래서 큰 양의 데이터가 영원히 저장될 수 있는 secondary storage가 제공된다.
한 예로 magnetic disk가 있다.
- 프로그램과 데이터를 저장할 수 있는 공간을 제공.
대부분의 프로그램은 메모리에 로드될 때까지 디스크에 저장된다. 그래서 많은 프로그램이 disk를 프로세스의 소스와 결과 지점으로 사용한다. 따라서 디스크 저장 관리가 컴퓨터 시스템에서 매우 중요하다.
register, main memory, magnetic disk 외에도 cache memory, CD-ROM 등이 존재하고 속도, 가격, 변동성 등에 차이가 존재한다.
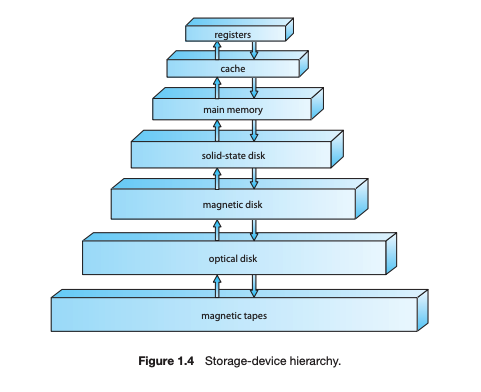
storage는 위 사진과 같은 계층구조를 가지는데 아래로 내려올 수록 가격은 싸지고 access time은 늘어난다. 요즘은 semiconductor memory를 쓰는 추세이다.
그리고 속도와 가격을 떠나서 volatile과 nonvolatile한 메모리가 존재하는데 백업이 없거나 배터리가 무제한이 아니라면 nonvolatile storage에 저장해놔야한다.
volatile 메모리는 상대적으로 빠르기 때문에 변동을 대비하여 사용하고 있다.
- 예를 들어 solid state disk는 volatile하기 떄문에 정보를 일단 solid에 저장하고 hidden magnetic hard disk를 가지고 있다.
- 그리고 power가 인터럽트 된다 싶으면, 컨트롤러가 RAM에서 데이터를 카피해서 magnetic disk에 저장해놓는다.
- 이후에 복구되면 RAM에 데이터를 다시 복사해놓는다.
- flash 메모리도 volatile의 한 예이다.
이와 같이 storage system은 이 모든 팩터를 잘 균형있게 관리해야한다.
1.2.3 I/O Structure
보통 컴퓨터에는 CPU와 다양한 device controller가 존재한다. 각각의 device controller는 특정 종류의 디바이스를 담당하게 되는데 종류에 따라 여러개의 device가 attach되기도 한다. device controller는 주변 장치와 로컬 버퍼 저장소 사이에서 데이터를 주고 받는 역할을 한다.
보통 OS는 각 device controller에 대핟아는 device driver를 가지고 있게 된다. 각각의 device driver는 컨트롤러를 이해하고 운영 환경에 대한 interface를 제공한다.
- 먼저, 드라이버가 컨트롤러에 있는 적당한 register를 로드한다.
- 컨트롤러가 레지스터에 있는 내용을 확인하고 액션을 선택한다.
- 컨트롤러가 디바이스에서 데이터 정보를 가져와서 local buffer로 옮긴다.
- 컨트롤러가 드라이버에게 interrupt를 보내서 operation의 끝남을 알린다.
- 드라이버가 컨트롤을 OS에게 반환하고 있다면 데이터도 반환한다.
이 interrupt driven I/O는 적은양에 작업에는 적합하지만 엄청난 양의 데이터가 운반될때는 불가능하다. 이 문제를 해결하기 위해 direct memory access(DMA)가 사용된다.
- I/O를 위한 버퍼, 포인터, 카운터를 준비한 후, 컨트롤러가 데이터 블락 전체를 buffer storage에서 memory로 운반한다.(CPU의 간섭 없이)
- only one interrupt 발생(block of data에 대한) rather than one interrupt per byte
- 훨씬 interrupt가 적게 발생합니다. 그러면 CPU는 그동안 다른 일하면 됩니다.
- io 디바이스를 위해 DMA가 cpu와 같이 역할을 대신 해준다
1.3 Computer-System Architecture
1.3.1 Single-Processor Systems
최근까지도 컴퓨터 시스템은 1개의 프로세서를 사용했었다. 이런 프로세서는 1개의 CPU가 general-purpose 명령어들을 처리하고 special purpose를 담당하는 processor가 따로 있다(예를 들어 디스크, 키보드, 그래픽 컨트롤러와 같이 device-specific processors의 형태로 존재한다.)
이런 special purpose processor들은 유저의 process를 담당하지 않고 한정된 명령어만 처리한다. 때로 이런 친구들은 OS가 관리하고 다음 태스크를 알려준다. 이 친구들은 하드웨어에 설치되어 있고 OS가 직접 processor이랑 소통할 수 없다. (?)
This arrangement relieves the main CPU of the overhead of disk scheduling.(?) 13p
이러한 1개의 general-purpose CPU를 가진 시스템을 single processor system이라고 한다.
1.3.2 Multiprocessor Systems
Multiprocessor Systems = parallel system = multicore system
최근에 컴퓨터 시장 지배함.
장점
- 처리량 증가
- 프로세서가 N개 늘어난다고 해서 N배 속도가 증가하는 것은 아니나 여전히 빨라진다.
- 같이 작업하기 위해 오버헤드(간접적인 처리 비용)가 발생하기 때문에 예상보다 조금 gain이 적다(둘이 작업할 때 2배 속도가 아닌 것과 같다)
- 경제성
- 멀티프로세서가 여러개의 단일프로세서보다 싸다.
- 왜냐하면 멀티프로세서는 peripherals(주변장치), 저장소, 파워를 공유하기 때문이다.
- 신뢰성 상승
- 함수가 나눠서 뿌려지면 하나의 실패가 전체를 멈추지 않고 그 과정을 느려지게 한다.
- 성공한 프로세서가 실패한 프로세서의 일을 다시 집어서 실행하면 그냥 속도 측면에서만 느려지지 멈추지는 않는다.
이런 increased reliability는 매우 중요
graceful degradation : 어떻게든 하드웨어를 버티면서 서비스를 부분적으로라도 제공하는 것
fault tolerant
- graceful degradation를 넘어서서 어떤 한부분이 고장나도 여전히 작동하는 것
- 이건 고장을 디텍트하고 분석하고 고칠수도 있으면 좋다.
CPU가 여러개 일때 프로세서를 두개 실행해서 결과 값이 다르면 멈추도록 했고 그 명령어를 다른 프로세서 페어로 넘겨줘서 다시 하도록.
- 비싸다
요즘 2가지 종류의 multi processor system 존재
- asymmetric multiprocessing
- 각 프로세서에 특정한 일을 부여
- 보스 프로세서가 존재해서 다른 프로세서에 일 부여
- symmetric multiprocessing(SMP)
- 보스가 없고 메모리는 쉐어하되 각각의 레지스터를 이용
- CPU 갯수만큼 프로세스 갯수를 늘릴 수 있다
- 단 데이타가 알맞은 프로세서에게 갈 수 있게 확인 필요
- 특정 DS를 사용하면 프로세스와 자원을 잘 공유하고 프로세서 간의 변동사항을 최소화 할 수 있다.
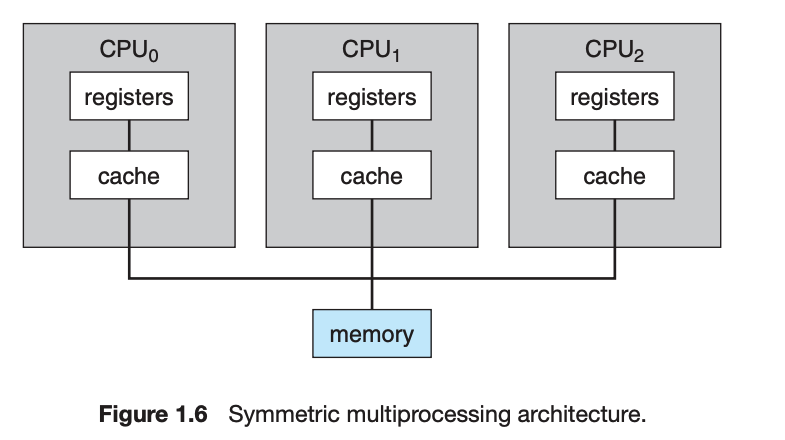 
Multiprocessing

Multiprocessing
- CPU를 늘려서 컴퓨팅 파워를 증가시킬 수 있다.
- UMA -> NUMA
- UMA(uniform memory access): CPU에서 RAM 접근할때 시간이 동일하게 걸린다.
- NUMA(non.) : 몇부분은 더 시간이 걸린다.(퍼포먼스 페널티)
- 이 문제는 오에스에서 해결(추후에 배움)
multiprocessor의 여러 형태
- multicore
- 요즘 트렌드는 CPU 싱글칩에 여러개의 core를 가지게 하는 multicore가 대세
- 칩 안에서 소통이 훨 빠르고, 파워도 적게 씀 (이득)
- 듀얼코어는 각각이 register와 local cache를 가지고 있다
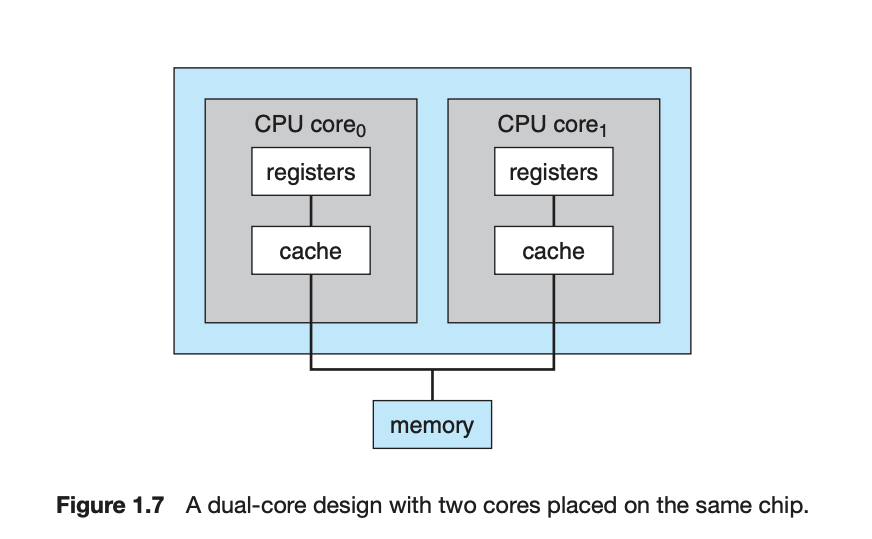
-
blade servers클자기만의 OS를 돌려서 자신만의 독립된 multiprocessor system을 가지고 있다.
-
clustered sytem
- 각각의 시스템(노드)이 존재하고 이게 로컬 네트워크나 빠른 interconnect로 묶여있다.
- high-availability
- 한두개의 클러스터가 문제가 생겨도 서비스가 계속 돌아감
- 이거는 redundancy를 통해서 가능함
- 각각이 서로를 관찰 가능한데 문제가 생기면 storage의 ownership을 가지고 와서 자기가 똑같은 작업을 실행
- 유저는 짧은 인터럽션만 봄
- 종류
- asymmetric clustering
- 하나 노드는 감시 나머지 작업
- symmetric
- 다 일하면서 서로 봐줘
- 장점
- 여러 시스템을 네트워크로 묶으면서 high performance computing environment 제공
- 클러스터에 있는 모든 원소(컴퓨터)가 일을 하기 때문에 완전 파워풀
- paralleization: 프로그램을 컴포넌트 단위로 쪼개서 각 컴퓨터에서 동시적으로 작업하게 하는 것
- 최종적으로 각 작업을 결과값을 합쳐서 반환한다.
- 이거는 여러 호스트에 대해서 한 저장소를 공유해야 때문에 소프트웨어가 필요하다
- 요즘 엄청 발전해서 엄청 떨어진 노드 간에도 소통이 가능하다.


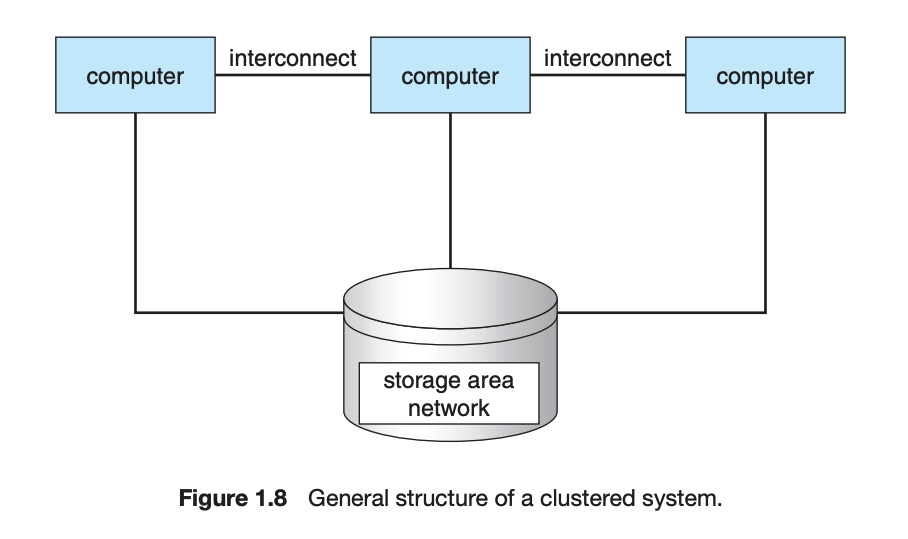
1.4 Operating System Structure
multiprogram
- 여러 일을 organize해서 CPU 활용도를 높임
- 유저는 보통 하나의 일만을 하지 않기 때문에
-
여러 job을 메모리에 쌓아놓는다  
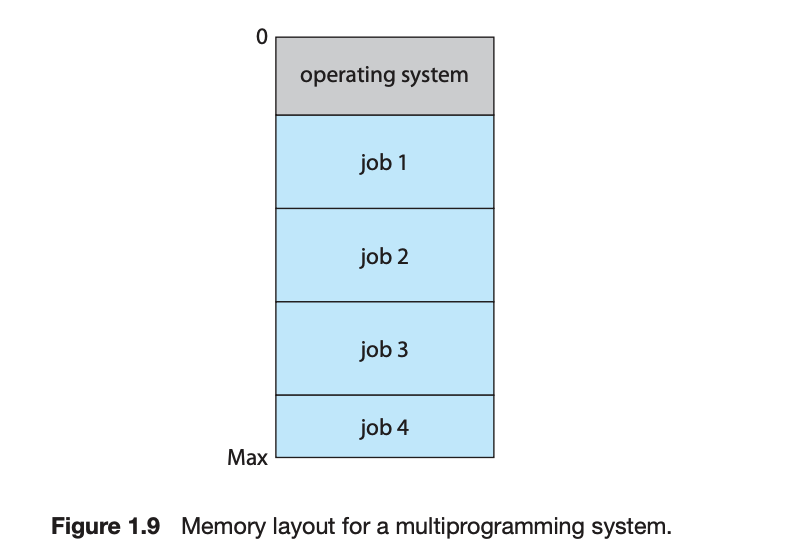
- 메인메모리가 일을 다 감당 못함 그래서 disk에 있는 job pool에 저장
- OS가 memory에서 job을 꺼내서 사용
- singleprogram은 일이 안끝나면 기다리지만 multi는 걍 다른 일 고고
- 마치 변호사가 고객이 있는한 여러 일을 번갈아 가면서 하듯
- Timesharing(Multitasking)
- CPU가 여러 일을 하는데 이 switch가 너무 빠르고 빈번해서 유저가 모든 프로그램과 interact가 가능
- 유저의 command에 대한 response time은 대체로 매우짧다(유저의 action이나 command가 간단(?)하기때문에)
- 그래서 각유저에게 신속하게 switch해서 반응해주기 떄문에 전체 시스템이 유저에게 집중하고 있다는 느낌을 준다(사실 아닌데)
- CPU는 각 유저에게 메모리의 작은 부분을 준다.
- 이때 유저당 메모리에 적어도 한개의 프로그램을 제공해주는데 이 프로그램이 loaded되고 execute되는 것을 process라고 한다.
- 우리가 초당 7개 정도 타이핑하는 속도가 너무 느려서 컴퓨터가 우리가 타이핑 하는 동안에도 다른 일을 번갈아가면서 한다.
- 이때 일이 너무 많다면 어떻게 해야겠는가? 결정을 내려야한다. 이를 job scheduling이라고한다
- timesharing이 훨씬 빠르다 왔다갔다가 엄청 빠르고 빈번하기 때문에
- 일단 timeshare이 가능하려면 response time이 빨라야한다
- swapping(프로세스가 메인메모리에서 디스크로 왔다갔다)
- virtual memory(완전히 메모리에 있지 않은 일을 처리?),ㅎ
1.5 Operating-System Operations
- OS 디자인이 매우중요하다
- 유저랑 시스템이 정보를 공유하기 때문에 하나 프로그램이 여럿 망칠 수 있다.
- 이거 방지 않는 것이 매우 중요
1.5.1 Dual-Mode and Multimode Operation
- mode로 컨트롤(유저모드, 시스템모드)
- mode bit이 존재
- boot했을때 kernel모드였다가 유저 애플리케이션 돌면 usermode였다가 interrupt 발생하면 다시 kernel모드로
- 듀얼모드로 에러유저를 방지
- 문제 이르킬거 같은 명령어를 privilieged instruction으로 구분하고 커넬모드에서만 실행
- 모드기 더 존재할 수도 있다
- virtual machine manager모드
- 유저랑 커넬 중간 정도의 priviliege
- System call은 유저 프로그램을 위해 OS에게 테스크를 부탁할 수 있게 해줌(kernel에서 할 수 있도록)
- 듀얼 모드에서는 유저 프로그램에서 문제가 발생하면 하드웨어가 OS를 가두고 그 프로그램을 멈추도록한다
- 유저 어플리케이션에서 kernel mode를 제공한다.
1.5.2 Timer
- infinite loop에 갇히거나 fail to return을 방지하기 위해서 timer을 사용
1.6 Process Management
- process vs program
- 프로세스는 일하는 주체 활발히
- 프로그램은 일 그 자체
- 프로세스는 주로 sequential하기 각 인스트럭션이 다음 인스트럭션 포인팅
- 프로세스는 Data & Code 뿐 아니라 state
1.7 Memory Management
- main memory에 CPU랑 IO 디바이스가 쓸 데이터가 들어있다
- 근데 메인 메모리 안커서 disk에서 mainmemroy로 데이터를 올렸다 내렸다 해야한다.
- 이때 컴퓨터가 효율적으로 잘 돌기 위해서 여러개의 적당한 프로그램을 메모리에 올려놔야한다.
- 이 때 만들어질 scheme을 위해 여러 고려사항이 있다
- 지금 무슨 메모리가 사용되고 누가쓰고
- 할당 디할당 필요
- 어떤 프로세스랑 데이터가 들어왔다 나갔다를 결정
1.8 Storage Management
- 유저한테 용이하게 하기 위해서 정보저장 체계의 unform, logicalview를 제공해준다.
- OS가 저장소의 보이는 구조를 추상화해서 만들어줬는데 이게 file이다.
- OS가 파일을 physical media랑 엮어준다
1.8.1 File-System Management
- 파일 시스템 관리가 OS의 가장 눈에 보이는 컴포넌트이다
- 여러 physical media에 인포메이션을 저장.
- 각각은 서로 다른 특성을 가지고 있고 각가은 다른 device에 의해서 컨트롤 됨.
- 파일이란 creator에 의해 연관된 정보들의 collection
- program + data
- OS는 tapes, disks, devices 같은 mass storage media를 관리하면서 파일이라는 컨셉을 도입했다.
- 파일은 디렉토리를 이룬다
- 어세스도 정해져있다.
1.8.2 Mass-Storage Management
- 결국 저장소인 디스크를 출발지와 목적지로 사용한다.
- 그래서 디스크 관리는 진짜 엄청 중요하다
- 때문에 OS는 disk management에 중요한 역할을 한다.
- free-space management
- storage allocation
- disk scheduling
- secondary storage는 진짜 자주 사용되지만 값때문에 여러 저장소가 사용된다.
- tertiary storage같은 친구들이다
- OS는 이 저장소를 올리고 내리고 하고 data를 secondary에서 tertiary storage로 옮겨주고 한다
1.8.3 caching
- 정보가 다른 곳에서 보관되다가 정보가 사용되면 더 빠른 저장소인 cache에 데이터가 잠깐 올라온다.
- 어떤 정보를 찾을때 우리는 cache를 제일 먼저 확인하게 된다.
- 없으면 일단 cache에서 카피를 가져온다.
- 그리고 programmable register가 있어서 그에 해당하는 알고리즘이 있어서 저장할 정보를 골라준다.
- CPU가 반복적으로 쉽게 접근할 수 있게 일부를 캐시에 저장해 놓는다.
<#Title#>
Subscribe via RSS