
(강화학습 입문) 2. 그리드월드와 다이나믹 프로그래밍 - 정책, 가치 이터레이션
by 줌코딩
3장 강화학습 기초 2: 그리드월드와 다이내믹 프로그래밍
- 알고리즘에서 접하는 DP는 분할기법을 이용하는 것으로 큰 문제를 해결하기 위해 문제를 작은 여러 문제로 나누는 것을 말한다.
- 이 과정에서 매번 같은 계산을 누적하지 않고 값을 저장하고 재사용한다.
MDP에서 DP의 과제
- 큰 문제는 무엇이고 작은 문제는 무엇인가?
- 반복되는 작은 문제는 어떻게 풀 것인가?
- 저장되는 값은 무엇인가?
주요개념 두개!
정책 이터레이션 : 다이나믹 프로그래밍으로 벨만 기대 방정식을 푸는 것 가치 이터레이션 : 벨만 최적 방정식을 푸는 것
다이내믹 프로그래밍과 그리드 월드
순차적 행동 결정 문제
- 벨만 방정식은 벨만 기대 방정식, 벨만 최적 방정식으로 나뉜다.
- 벨만 방정식의 목표는 최적 가치함수와 최적 정책을 찾는 것이다.
그렇다면 벨만 방정식을 푼다는 것은 어떤 의미인가?
- 보상을 최대로 받는 가치함수인 v*를 찾는 것이다.
다이내믹 프로그래밍
- 벨만 방정식에서 DP는 아래와 같이 가치함수를 계속해서 업데이트 하는 용도로 사용된다.

격자로 이뤄진 간단한 예제: 그리드월드
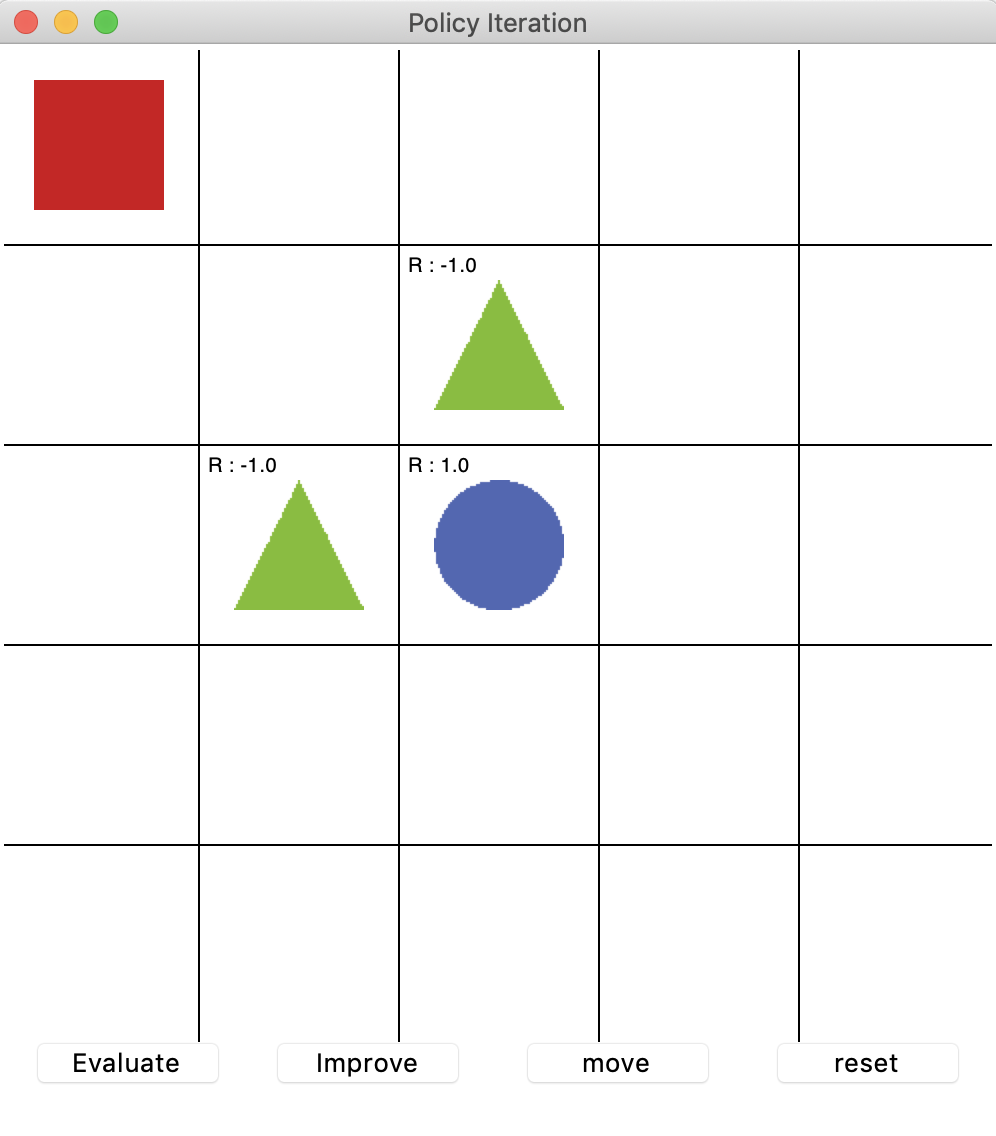
위의 그림과 같이 DP를 통해 에이전트(빨간 네모)가 초록 세모를 피해서 파란 동그라미에 도달하는 길을 찾는 최적 정책을 찾는 과정을 살펴보자.
다이내믹 프로그래밍 1: 정책 이터레이션
정책 이터레이션
- 정책이란 에이전트가 모든 상태에서 어떻게 행동할지에 대한 정보를 말한다.
- 정책 이터레이션은 평가와 발전을 통해 최적 정책을 찾는 과정을 말한다.
- 초기에는 무작위로 행동을 정하는 정책이 들어간다.
정책 평가
- 가치함수는 정책이 얼마나 좋은지 판단하는 해준다.
- 가치함수를 통해 현재 정책 p를 따라갔을 때 받을 보상을 알려준다.
여기서 DP가??
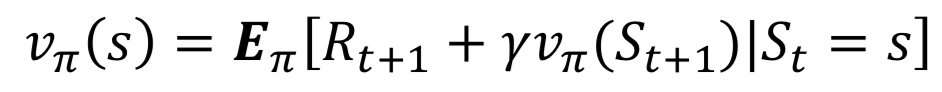
- 벨만 기대 방정식은 위와 같다.
- 주변 상태의 가치함수와 한 타임스텝의 보상만 고려해서 다음 가치함수를 계산한다.
- 즉, 매 이터레이션마다 가치함수가 업데이트되고 언젠가 참값으로 수렴하게 된다.
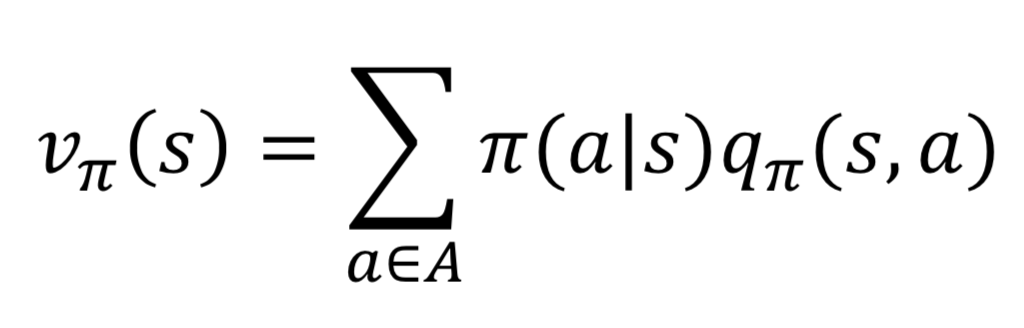
- 위의 방정식의 의미는 현재의 가치함수를 s에서 취할 수 있는 액션의 가치에 s’으로 갔을 때의 보상과 s’ 상태의 가치를 더한 값을 곱한 것을 의미한다.
- 하지만 여기서 매 이터레이션마다 정책이 업데이트 되므로 가치함수도 시간의 흐름에 따라 나타낼 수 있다.
- 아래 수식은 s에서 각 a의 가치 * s에서 a라는 행동의 보상과 a를 통해 얻어진 s’의 가치의 합을 다 더해서 새로운 가치함수를 생성한다.
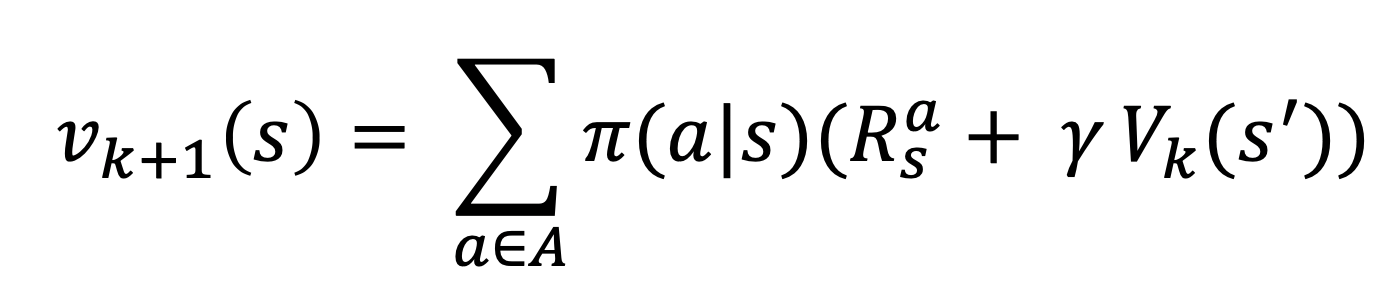
즉, 정책을 구하는 과정은 다음과 같이 나타낼 수 있다.
- 1.k번째 가치함수 행렬에서 현재 상태 s에서 갈 수 있는 다음 상태 s’ 에 저장되어 있는 가치함수를 불러옵니다.
- 2.거기에 감가율을 곱하고 그 상태로 가는 행동에 대한 봉상을 더합니다.
- 3.2번에서 구한 값에 그 행동을 할 확률, 즉 정책 값을 곱합니다.
- 4.3번을 모든 선택 가능한 행동에 대해 반복하고 그 값들을 더합니다.
- 5.4번 과정을 통해 더한 값을 k+1번째 가치 함수 행렬에 상태 s자리에 저장합니다.
- 6.이것을 모든 s에 대해서 반복합니다.
위를 무한히 반복하면 참 가치함수를 발견할 수 있다.
정책 발전
- 여기서 소개하는 정책 발전 기법은 탐욕 정책 발전 기법이다.
- 큐함수를 다음과 같이 정의하고 진행한다.
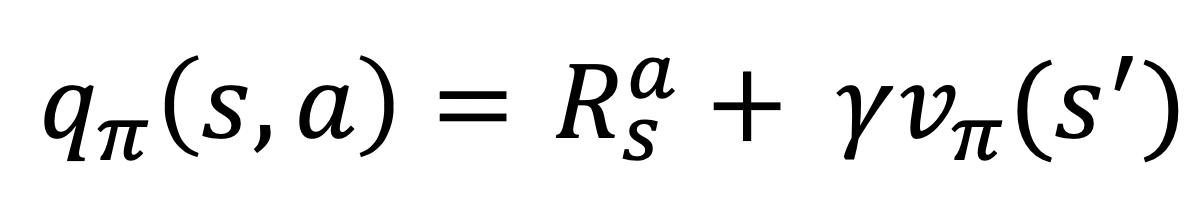
- 큐함수는 사방향의 값은 해당 위치로 이동했을 때의 보상과 이동 후 위치의 가치를 더한 것을 반환한다.
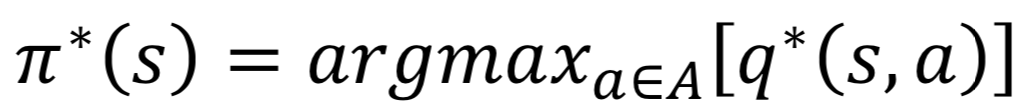
- 이를 바탕으로 이들 중 max값을 저장하게 함으로써 정책을 발전 시킨다.
policy_evaluation
정책 평가는 다음과 같이 진행된다.
for action in self.env.possible_actions:
next_state = self.env.state_after_action(state, action)
reward = self.env.get_reward(state, action)
next_value = self.get_value(next_state)
value += (self.get_policy(state)[action] *
(reward + self.discount_factor * next_value))
여기서 해당 state의 값은 모든 가능한 액션의 값 더하는 다음 식을 통해서 구해진다.
value += (self.get_policy(state)[action] *
(reward + self.discount_factor * next_value))
policy_improvement
정책 평가를 통해서 새로운 가치함수가 얻어진다. 이때 정책을 그에 맞춰서 업데이트 하는 방법이 탐욕정책 발전(가치가 가장 높은 하나의 행동을 선택하는 것)이다.
다음과 같은 과정을 통해 temp라는 값을 구해주고
for index, action in enumerate(self.env.possible_actions):
next_state = self.env.state_after_action(state, action)
reward = self.env.get_reward(state, action)
next_value = self.get_value(next_state)
temp = reward + self.discount_factor * next_value
이중 가장 큰 값을 넣어준다.
if temp == value:
max_index.append(index)
elif temp > value:
value = temp
max_index.clear()
max_index.append(index)
get_action
이 중에 무작위로 하나의 값(0~1 사이)이 호출되면 그 값을 기반으로 높은 확률의 액션이 하나 선택받게 된다.
for index, value in enumerate(policy):
policy_sum += value
if random_pick < policy_sum:
return index
정책 이터레이션 코드 실행
첫 평가 후 결과이다.
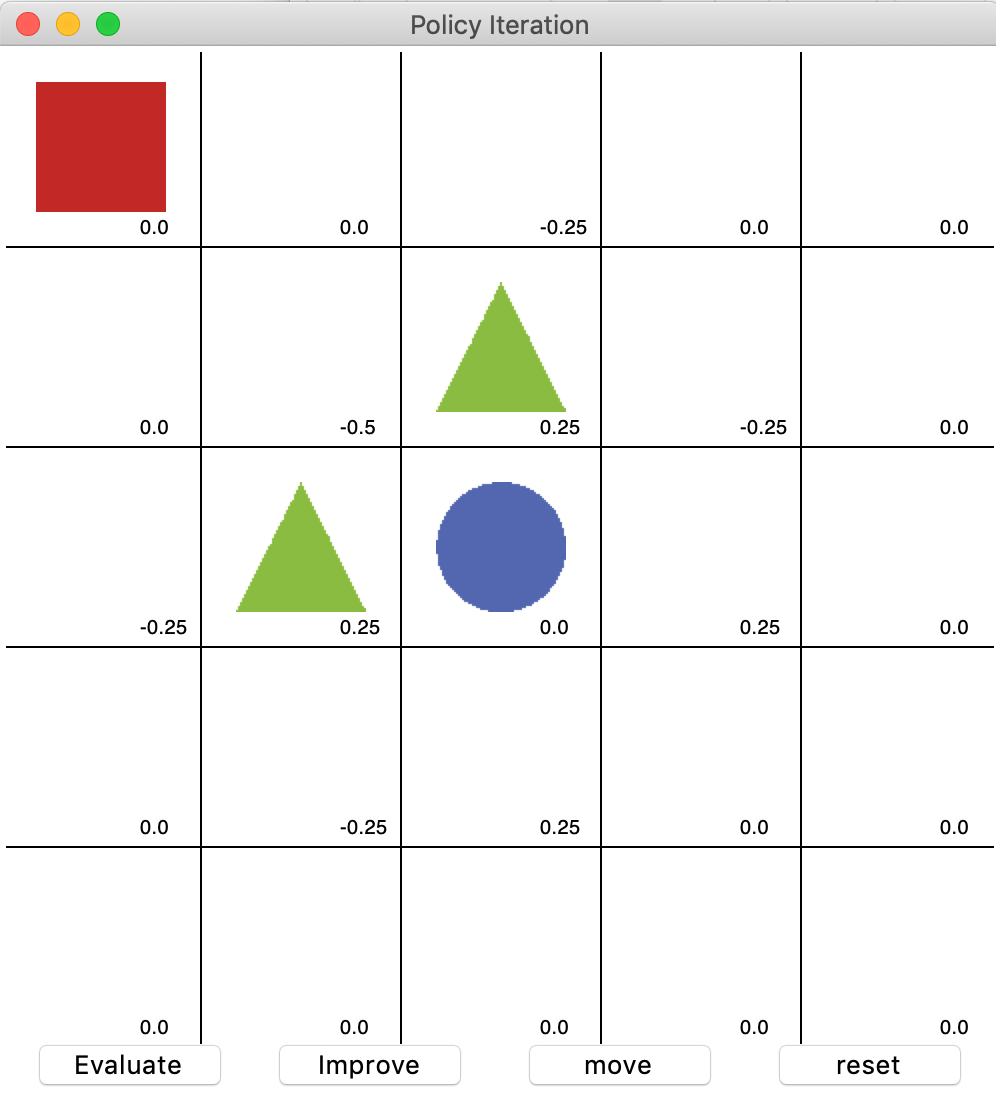
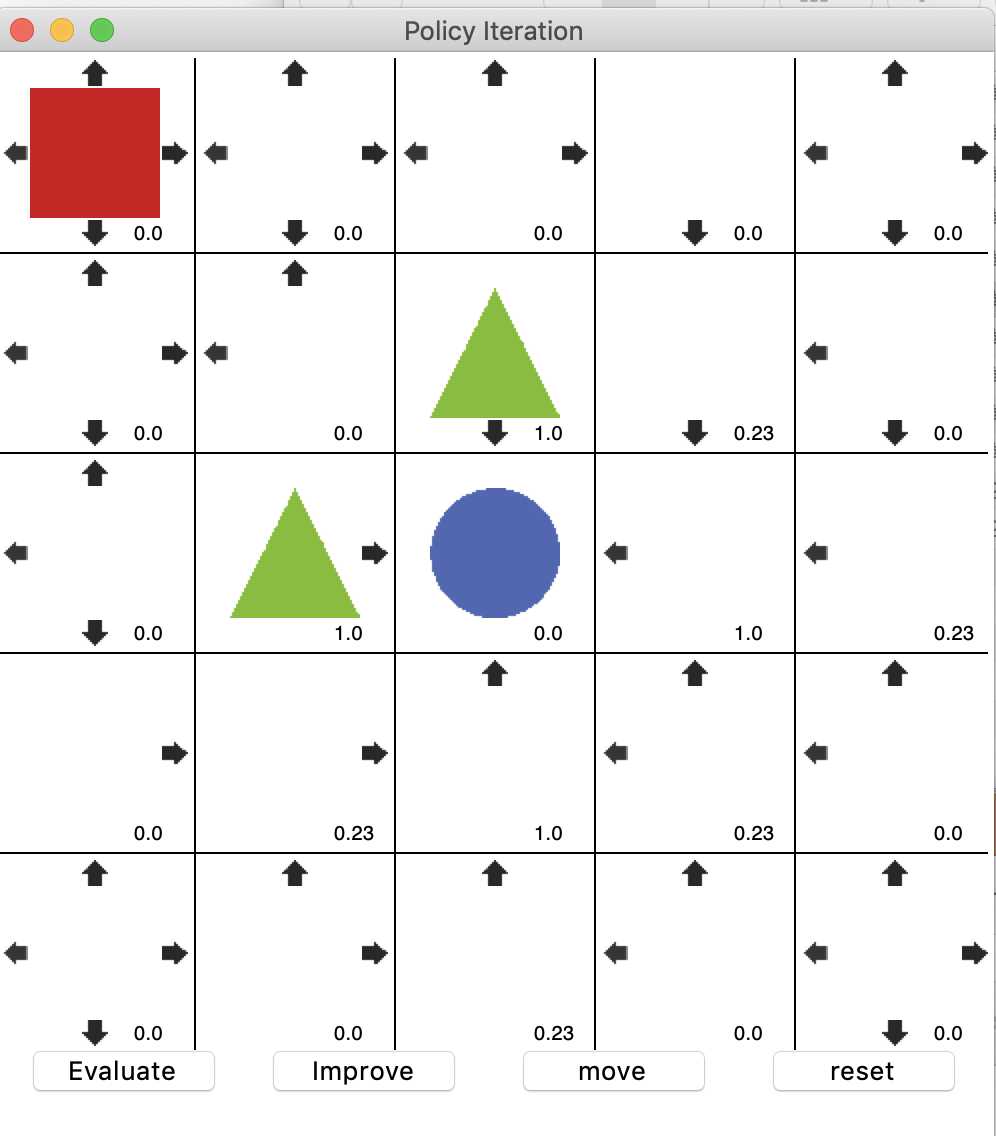
첫 평가 후 발전 시켰다. 아직은 판단이 어렵다.
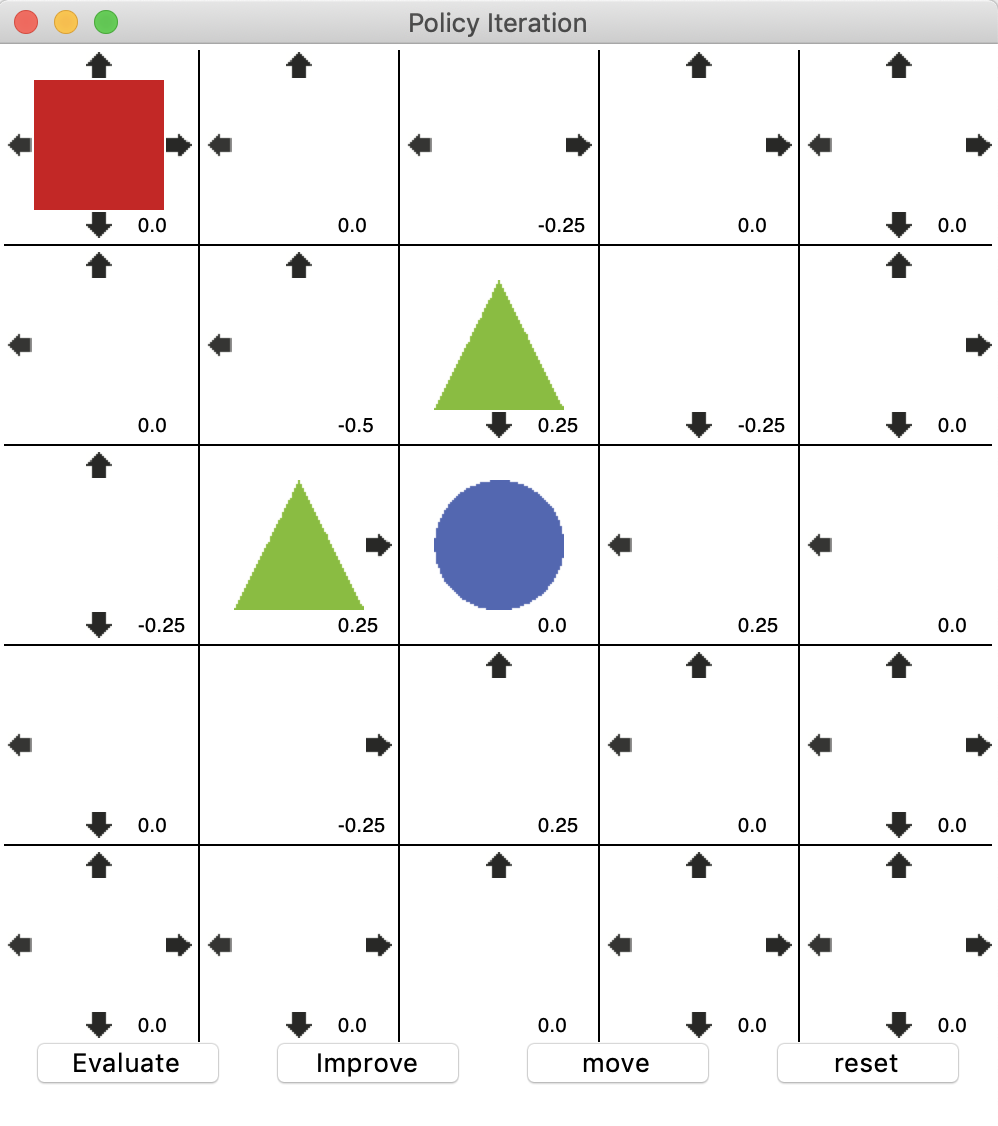
평가와 발전을 한번씩 더 진행했다.
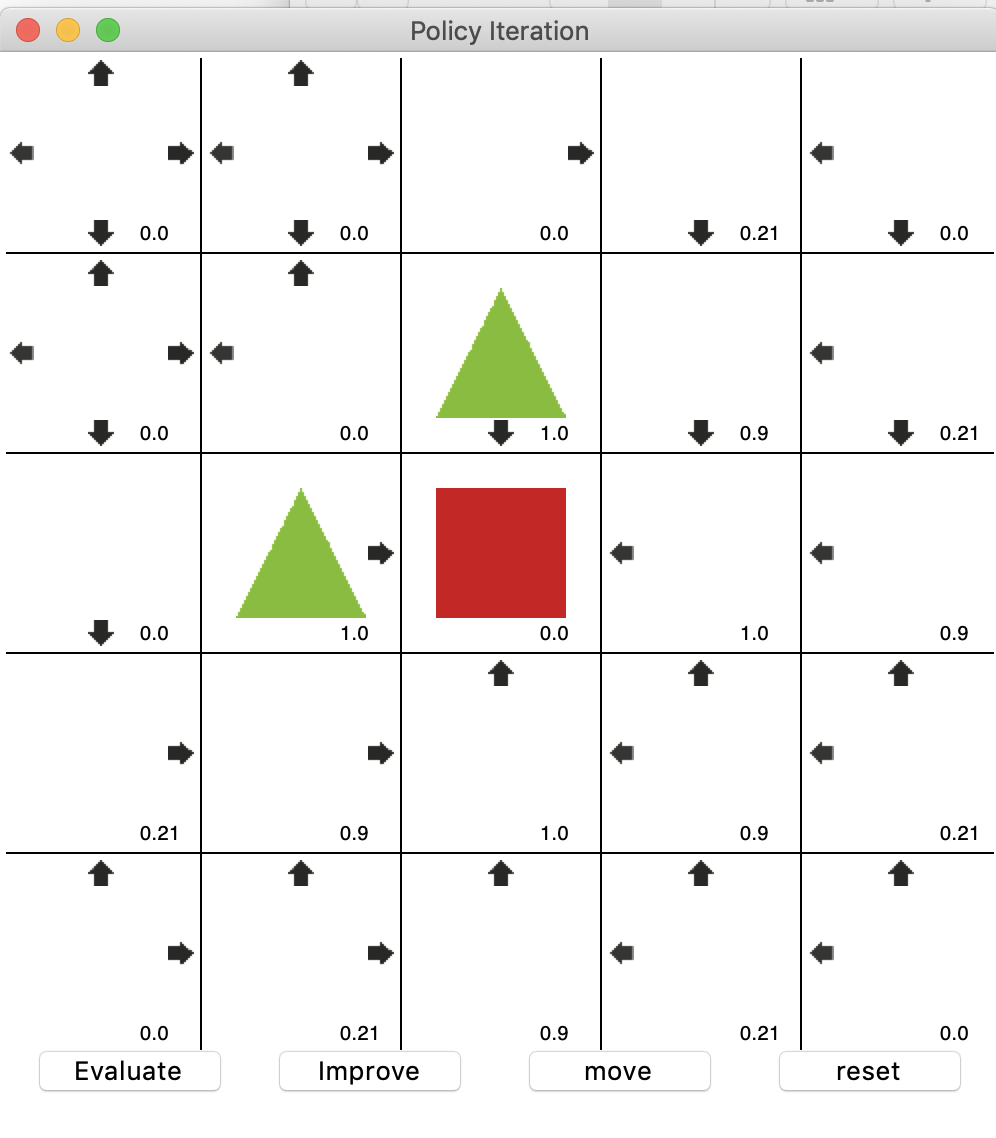
이동시켰을 때의 결과이다.
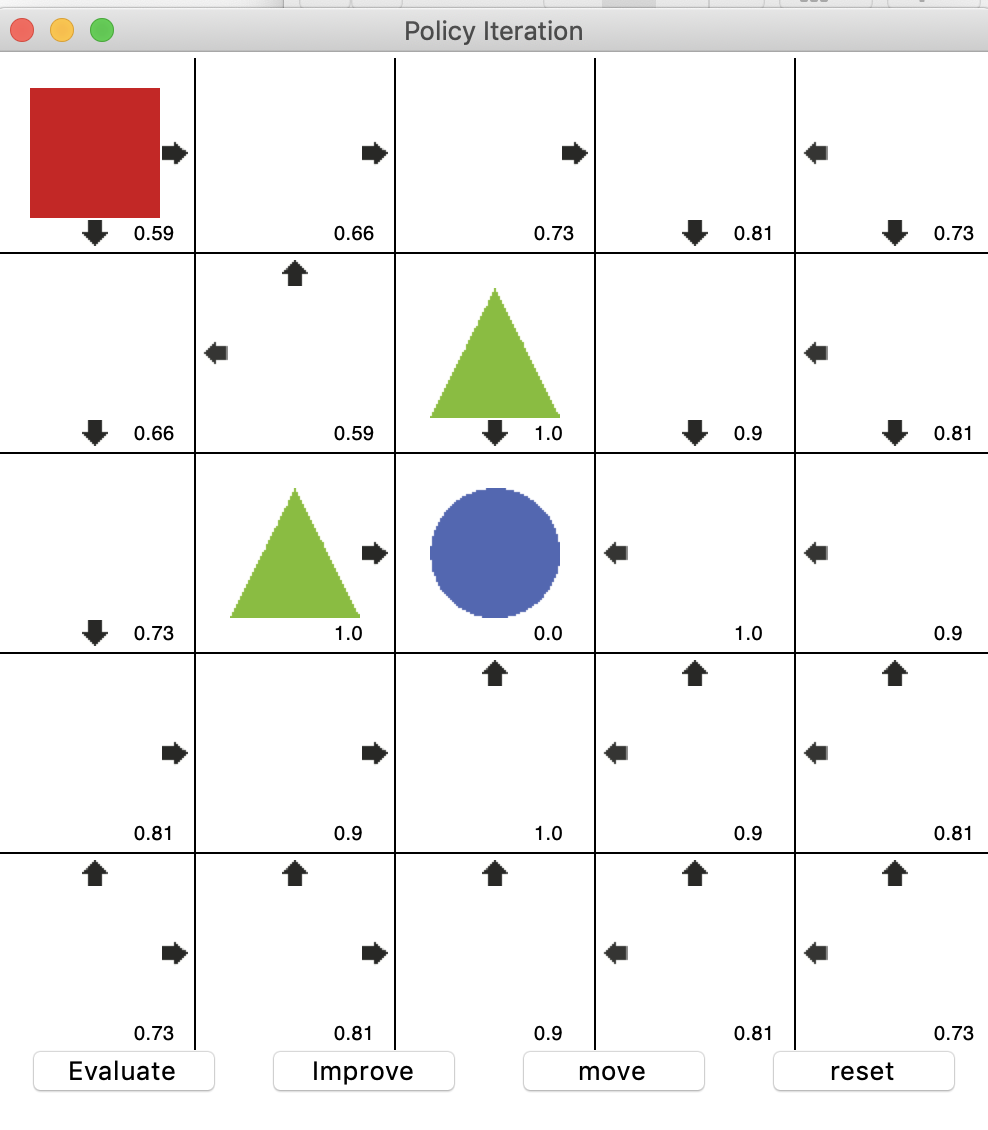
위의 평가와 발전을 반복하다보면 값이 변하지 않고 값이 수렴하게 되는 상태에 이른다. 이때를 최적 정책이라고 볼 수 있다.
다이내믹 프로그래밍 2: 가치 이터레이션
벨만 최적 방정식과 가치 이터레이션
가치 이터레이션은 정책을 발전시킬 필요가 없다.
- 1.먼저 가치함수를 최적 정책에 대한 가치함수라고 가정하고
- 2.반복적으로 계산하면
- 3.결국 최적 정책에 대한 참 가치함수를 찾게 된다.
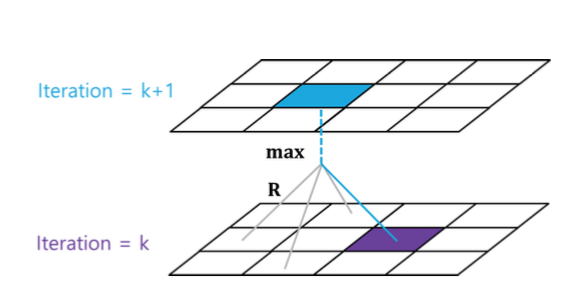
가치함수는 현재 상태에서 가능한 액션의 보상과 이동한 곳의 가치를 한 데 다 모아주고
for action in self.env.possible_actions:
next_state = self.env.state_after_action(state, action)
reward = self.env.get_reward(state, action)
next_value = self.get_value(next_state)
value_list.append((reward + self.discount_factor * next_value))
이들 중 max값으로 업데이트 시킨다.
next_value_table[state[0]][state[1]] = round(max(value_list), 2)
가치 이터레이션 코드 실행
다음은 각 가치 이터레이션을 진행할 때마다 업데이트 되는 결과를 보여주낟.
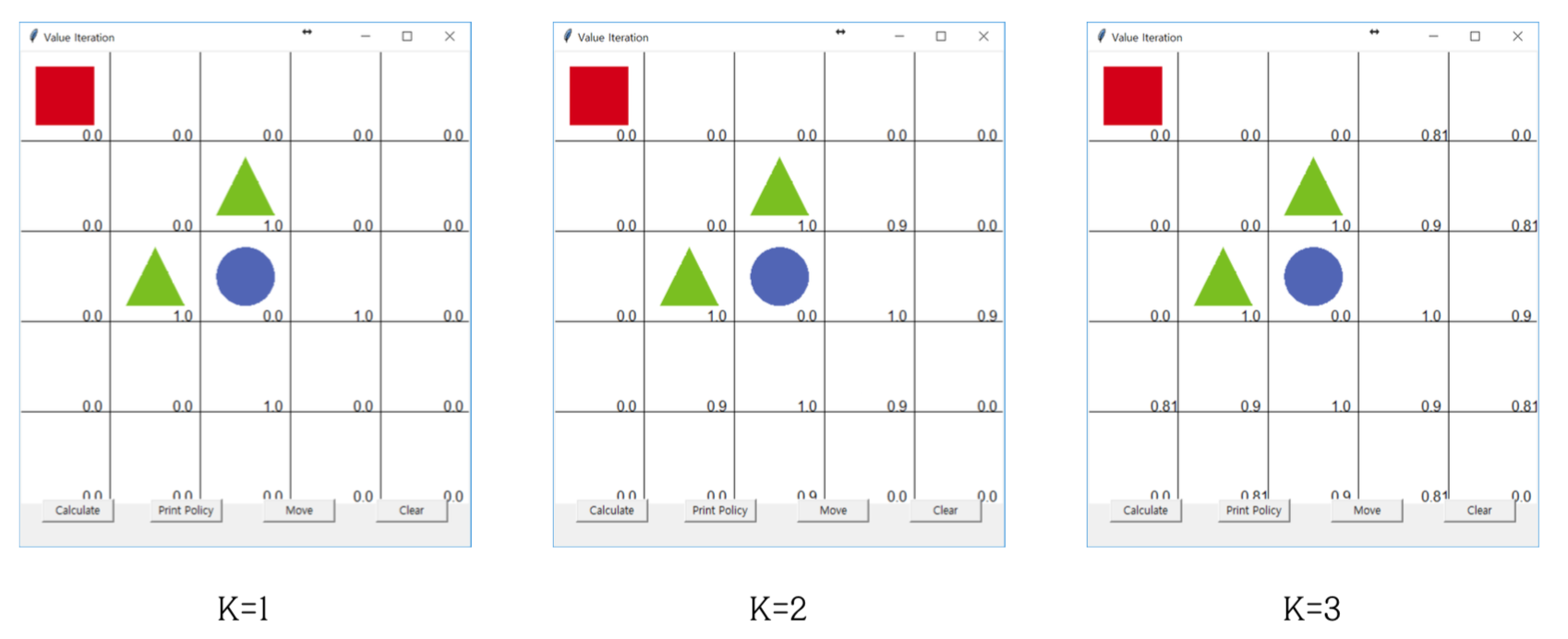
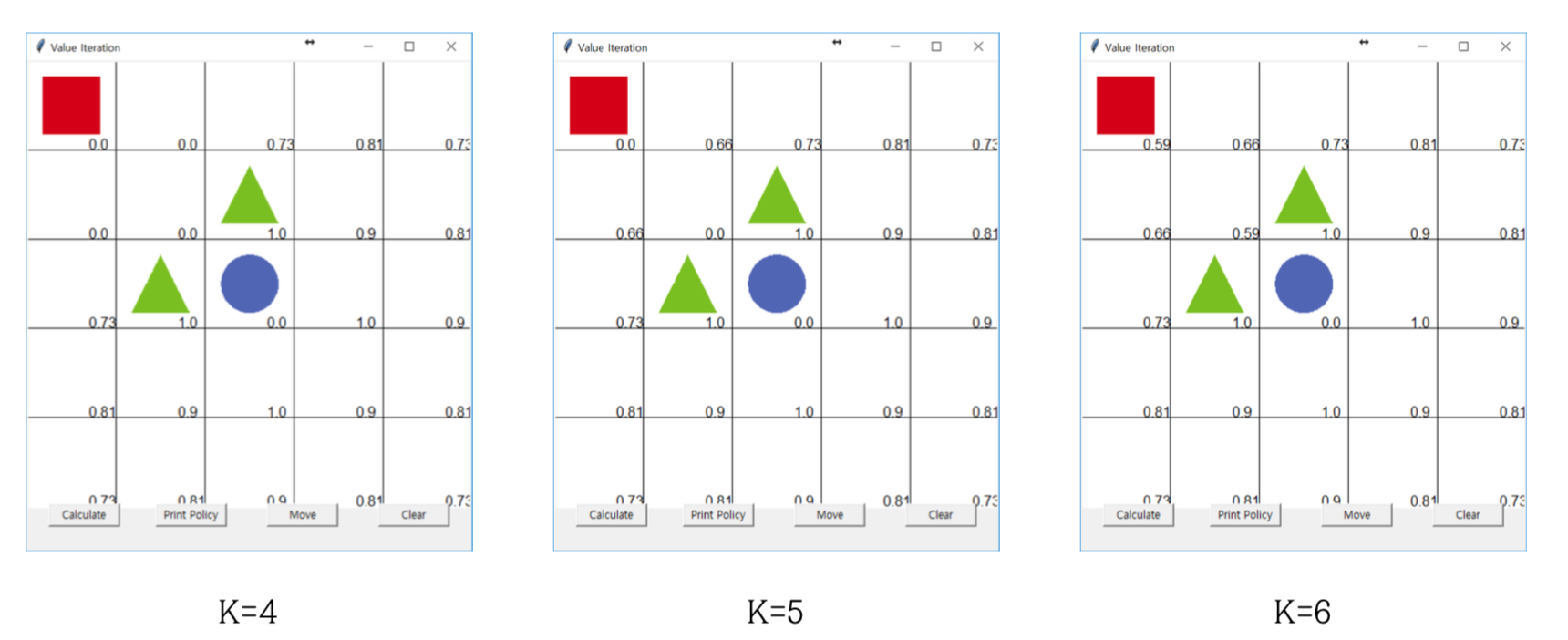
이를 기반으로 다음과 같이 행동을 결정할 수 있는 기준을 만들게 된다.
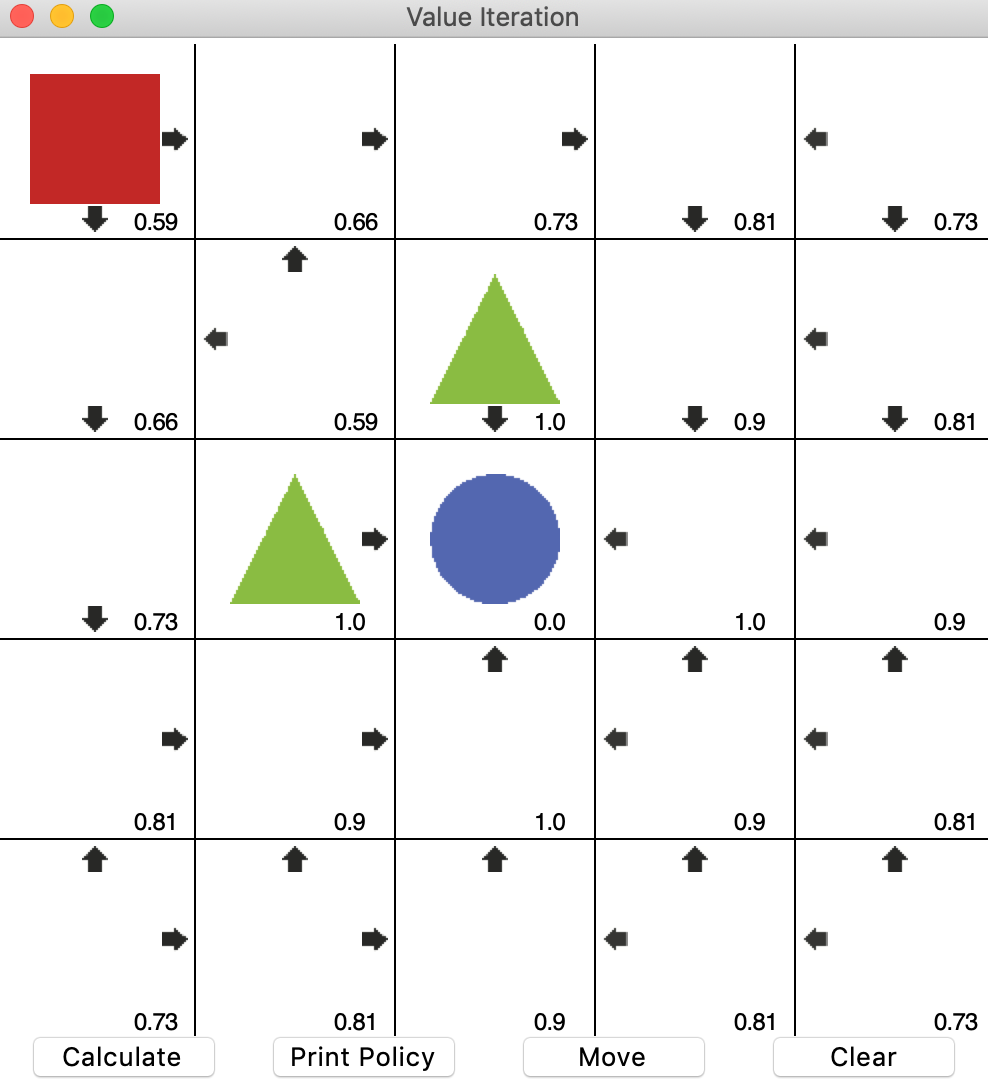
다이내믹 프로그래밍의 한계와 강화학습
다이내믹 프로그래밍의 한계
- DP는 계산을 빠르게 하는 것이지 “학습”을 하는 것은 아님
- 계산복잡도가 상태 크기의 3제곱이며 차원이 늘어나면 상태의 수가 지수적으로 증가
- 보상과 상태 변환 확률을 안다는 전제 하에만 가능
모델 없이 학습하는 강화학습
- 상태 변환 확률과 보상을 미리 모델링 하지 않고도 환경과의 상호작용을 통해 입력과 출력 사이의 관계를 학습한다.
- 결국 학습의 특성상 모든 상황에서 동일하게 작동한다고 보장할 수 없지만 많은 복잡한 문제에서 모델이 필요없다는 것이 장점이다.
느낀점
어제는 요즘 알고리즘 공부와 이것을 병행하며 오는 스트레스 때문에 그냥 이도저도 아닌 하루를 보냈다.(차라리 쉴걸…) 강화학습 공부는 안하면서 해야지하면서 스트레스만 받고 알고리즘은 벽에 부딪히게 되니까 힘이 빠지기 시작했다.
그래도 다시 마음 잡고 달린 오늘 책 잘 읽고 정리 장한 것에 매우 감사하고 만족한다.
막상 공부해보니 빨리 더 공부해보고 싶을 정도로 내용이 재미있다. 저번에 이해하지 못했던 벨만 어쩌구 알고리즘도 잘 이해하게 된 것 같아서 만족스럽다 ㅎㅎ
Subscribe via RSS